'개발/자바'에 해당되는 글 41건
- 2009.09.15 자바 암호화
- 2009.09.14 자바 정리 참고 1 1
- 2009.09.08 Java DES/TripleDES 암호화 2
- 2009.05.22 JMeter
- 2009.04.14 JAAS(Java Authentication and Authorization Service) 개요
- 2009.03.17 [java][성능] JVM GC와 메모리 튜닝
- 2009.03.17 미리 보는 미래 개발환경「자바SE 6
- 2009.03.17 JDK 5.0 에서의 새로운 변화
- 2009.02.05 주민등록 검사의 원리
- 2009.02.04 jaxp를 이용한 xmlutil
JCE(Java Cryptography Extension)란 이름의 프레임워크가 바로 그놈이다.
J2SE 1.4 이후부터는 JCE 1.2.2가 기본적으로 포함되어 있어서 별다른 라이브러리를 추가해주지 않아도 사용할 수 있다.
초기 버젼인 JCE 1.2는 미국 보안법(?)인가에 걸려서 국내에서는 사용할 수가 없었다. (무기밀매와 똑같은 처벌을 한다는 소문이..)
JCE 1.2.1이 나오면서 제한이 풀어져서, 세계적으로 많이(?) 사용하게 되었다.
그런데 이 JCE 1.2.1 버전의 자체 디지털 서명이 2005년 7월 27일쯤인가 만료가 되서, 2005년도에 파란을 한번 일으킨적도 있다.
(그럼 만료기간을 어떻게 알수 있을까? 쉽게 알려면, 자신이 사용하는 파일의 정보를 보면 된다.
자신이 사용하는 자바 관련 디렉토리에서 jce.jar를 풀어보면 META-INF에 JCE_RSA.RSA 파일이 있을것이다. 이 파일을 보면 알 수 있는데, 윈도우 환경에서 이 파일의 확장자를 "p7s"로 변경하면 열어볼 수 있다.)

이 JCE를 사용하지 않아도, 자체적으로 구현해서 마음껏 암호학의 세계를 여행할 수 있지만, 시간에 쫓기는 분들을 위해서 간단히 사용법을 알아보도록 하자.
암호화에는 크게 블럭 암호화(block encryption)와 스트림 암호화(stream encryption)가 있는데, 여기서는 가장(?) 많이 쓰이는 블럭 암호화에 대해서 알아보도록 하겠다.
블럭 암호화는 말 그대로 데이터를 정해진 블럭으로 나눈후 해당 블럭을 암호화하는것이다.
대표적으로 DES/3DES/AES/SEED 등이 있다.
DES(Data Encryption Standard)는 Lucifer를 보완하여 IBM에서 개발한 블럭암호 알고리즘이다.
64비트 입력 블럭을 56비트 비밀키를 사용하여 암호화하는 알고리즘이다.
전세계적으로 널리 사용되었다가, 56비트라는 짧은 키(key)로 인해 안전하지 않다고 보는 견해가 많아져서, 요즘은 AES한테 밀리는 추세이다.
3DES(Triple Data Encryption Standard)는 DES의 단점을 보완하기 위해서 기존의 DES 방식을 3번 적용(암호화->복호화->암호화)시킨것으로 그 과정에 따라서 56비트의 배수로 암호화 복잡도가 증가한다고 한다.
이 3번의 암복호화 즉, Encryption->Decryption->Encryption을 첫글자를 따서 DESede라 명칭하기도한다.
AES(Advanced Encryption Standard)는 현재 미국 정부 표준으로 지정된 블럼 암호화 알고리즘으로서, DES를 대체하고 있다.
키(key)의 크기는 128, 160, 190, 224, 256비트를 사용할 수 있으며, 현재 미국 표준으로 인정받은 것은 128비트이다.
(JCE에서 제공하는것도 128비트밖에 안될지도...)
SEED는 한국정보보호진흥원을 중심으로 국내 암호 전문가들이 참여하여 만든, 순수 국내기술 블럭암호화 알고리즘이다.
(SEED는 다음에 한번 구현에해보기도 하고 오늘은 다루지 않겠다.)
블럭 암호화를 하기 위해서는 당연히 원문(plain text)이 있어야하고, 암화하 하기 위한 키(key)가 있어야한다.
그리고 블럭 암호화 운용모드에 따라서 IV(Initialization Vector)가 필요하기도 하다.
이 키(key)에 따라서 대칭키 암호화와 비대칭키 암호화로 나눌 수 있다.
대칭키 암호화는 암호화키와 복호화키가 동일하다. 속도가 빠른 장점이 있으니 키(key)를 분배하기 어렵다.(키가 누출되면 암호화 자체가 의미가 없어진다.)
비대칭키 암호화는 키(key) 분배 문제때문에 개발되었는데, 암호화와 복호화키가 다르다. 즉, 공개키(PublicKey), 개인키(PrivateKey)가 따로 생성된다.
간단히 설명하자면, 멀리 떨어진 시스템에서 사용할때에, 이 2가지를 결합하여 사용하고 있다.
대칭키 암호화에 사용할 키(key)를 생성한다음, 비대칭키 암호화를 이용해서 그 키를 분배한다.
키가 안전하게 분배되면 대칭키 암호화를 이용해서 서로 암호화된 문서를 주고 받고 하는것이다.
(비대칭키 암호화가 대칭키 암호화보다 느리기 때문에 키분배에만 사용한다.)
앞에 설명한 DEs/3DES/AES/SEED는 대칭키 암호화 알고리즘이다. 비대칭키 암호화 알고리즘은 RSA(Rivest Shamir Adleman)가 있다.(사람 이름 첫글자를 딴것임)
이제 한번 구현해보도록 하자.
(바이트들을 화면에 출력하기(?) 위해 ByteUtils 클래스를 사용하겠다. 첨부파일을 참조하도록 하자)
1. 암호화에 사용할 키(key) 만들기
- 키를 만드는 방법은 랜덤하게 동적으로 만드는 방법과, 정해진 키를 읽어와서 만드는 방법이 있다. 두 기능을 하는 메소드를 만들어보자.
01.package test.cipher; 02. 03.import java.security.InvalidKeyException; 04.import java.security.Key; 05.import java.security.NoSuchAlgorithmException; 06.import java.security.spec.InvalidKeySpecException; 07.import java.security.spec.KeySpec; 08. 09.import javax.crypto.Cipher; 10.import javax.crypto.KeyGenerator; 11.import javax.crypto.SecretKey; 12.import javax.crypto.SecretKeyFactory; 13.import javax.crypto.spec.DESKeySpec; 14.import javax.crypto.spec.DESedeKeySpec; 15.import javax.crypto.spec.IvParameterSpec; 16.import javax.crypto.spec.SecretKeySpec; 17. 18.import kr.kangwoo.util.ByteUtils; 19.import kr.kangwoo.util.StringUtils; 20. 21.public class CipherTest { 22. 23. /** 24. * <P>해당 알고리즘에 사용할 비밀키(SecretKey)를 생성한다.</P> 25. * 26. * @return 비밀키(SecretKey) 27. */28. public static Key generateKey(String algorithm) throws NoSuchAlgorithmException { 29. KeyGenerator keyGenerator = KeyGenerator.getInstance(algorithm); 30. SecretKey key = keyGenerator.generateKey(); 31. return key; 32. } 33. 34. /** 35. * <P>주어진 데이터로, 해당 알고리즘에 사용할 비밀키(SecretKey)를 생성한다.</P> 36. * 37. * @param algorithm DES/DESede/TripleDES/AES 38. * @param keyData 39. * @return 40. */41. public static Key generateKey(String algorithm, byte[] keyData) throws NoSuchAlgorithmException, InvalidKeyException, InvalidKeySpecException { 42. String upper = StringUtils.toUpperCase(algorithm); 43. if ("DES".equals(upper)) { 44. KeySpec keySpec = new DESKeySpec(keyData); 45. SecretKeyFactory secretKeyFactory = SecretKeyFactory.getInstance(algorithm); 46. SecretKey secretKey = secretKeyFactory.generateSecret(keySpec); 47. return secretKey; 48. } else if ("DESede".equals(upper) || "TripleDES".equals(upper)) { 49. KeySpec keySpec = new DESedeKeySpec(keyData); 50. SecretKeyFactory secretKeyFactory = SecretKeyFactory.getInstance(algorithm); 51. SecretKey secretKey = secretKeyFactory.generateSecret(keySpec); 52. return secretKey; 53. } else { 54. SecretKeySpec keySpec = new SecretKeySpec(keyData, algorithm); 55. return keySpec; 56. } 57. } 58.}위 코드는 일단 정상(?) 작동하는데, 맞게 구현하지는 아직 잘 모르겠다. (내공이 부족하여 혹시 틀린부분이 있으면 지적바란다.)
2. DES 암호화/복호화 해보기
- DES 암호화/복화화를 하기위해선 Cipher 클래스를 사용하면 된다.
- Cipher cipher = Cipher.getInstance("DES/ECB/NoPadding"); 이런씩으로 "암호화알고리즘/운용모드/패딩"으로 사용하면 된다.
- DES는 암호화키가 64비트이므로 64비트 키를 생성하자
(예리한 분은 여기서 의문을 가질것이다. 위~에서 설명할때 DES는 56비트 키라고 했는데, 왜 갑자기 여기서는 64비트라고 우기는가에 대해서...
설명하자면, 64비트의 키(외부키) 중 56비트는 실제의 키(내부키)가 되고 나머지 8비트는 거사용(?) 비트로 사용된다고 한다.)
01.public static void main(String[] args) throws Exception { 02. Key key = generateKey("DES", ByteUtils.toBytes("68616e6765656e61", 16)); 03. String transformation = "DES/ECB/NoPadding"; 04. Cipher cipher = Cipher.getInstance(transformation); 05. cipher.init(Cipher.ENCRYPT_MODE, key); 06. 07. String str = "hello123"; 08. byte[] plain = str.getBytes(); 09. byte[] encrypt = cipher.doFinal(plain); 10. System.out.println("원문 : " + ByteUtils.toHexString(plain)); 11. System.out.println("암호 : " + ByteUtils.toHexString(encrypt)); 12. 13. cipher.init(Cipher.DECRYPT_MODE, key); 14. byte[] decrypt = cipher.doFinal(encrypt); 15. System.out.println("복호 : " + ByteUtils.toHexString(decrypt)); 16.}* 실행 결과
원문 : 68656c6c6f313233
암호 : 51d6aa8bcc176819
복호 : 68656c6c6f313233
실행해보면 암호화/복호화가 잘되는것을 알 수 있다.
DES는 암호화 알고리즘이고, ECB는 뭘까? 운용모드라고 했는데, http://blog.kangwoo.kr/13 여기에 퍼온글이 있으니 참조하기 바란다.
패딩(padding)은 말 그대로 패딩인데, 번역하면 채워넣기, 모자란만큼 채워넣는 역할을 한다. DES는 블럭 암호화 알고리즘이다.
그래서 암호화 할라면 블럭이 필요한데, DES 경우 64비트가 한 블럭을 형성한다. 그런데 입력한 데이터가 64비트가 안된다면 어떻게 될까?
궁금하면 "hello123" 을 "hello"으로 바꾼다음 실행해보자. 아마 다음과 같은 에러가 발생할 것이다.
* 실행 결과
Exception in thread "main" javax.crypto.IllegalBlockSizeException: Input length not multiple of 8 bytes
입력한 데이터가 8 bytes 즉, 64비트가 아니니 배째라는것이다.
그러면 정상작동을 하기위해서는 블럭크기의 배수만큼 나머지 데이터를 채워줘야하는데 그 역할을 하는게 패딩이다.
"DES/ECB/NoPadding"을 "DES/ECB/PKCS5Padding"을 바꾼다음 실행해보자.
이제 데이터가 64비트가 아니어도 정상작동한다. 그래서 귀찮으면 가능한한 패딩을 해주게 하면 좋다.
(운용 모드가 OFB/CFB일 경우 NoPadding을 사용해도 상관없다. IV를 이용해서 처리할때 필요가 없어지기때문이다. 믿거나 말거나)
3. DESede 암호화/복호화 해보기
- DES와 별반 차이 없다. 키 크기가 64비트 * 3 = 192비트로 늘어난것밖에 없다.
01.public static void main(String[] args) throws Exception { 02. Key key = generateKey("DESede", ByteUtils.toBytes("696d697373796f7568616e6765656e61696d697373796f75", 16)); 03. String transformation = "DESede/ECB/PKCS5Padding"; 04. Cipher cipher = Cipher.getInstance(transformation); 05. cipher.init(Cipher.ENCRYPT_MODE, key); 06. 07. String str = "hello123"; 08. byte[] plain = str.getBytes(); 09. byte[] encrypt = cipher.doFinal(plain); 10. System.out.println("원문 : " + ByteUtils.toHexString(plain)); 11. System.out.println("암호 : " + ByteUtils.toHexString(encrypt)); 12. 13. cipher.init(Cipher.DECRYPT_MODE, key); 14. byte[] decrypt = cipher.doFinal(encrypt); 15. System.out.println("복호 : " + ByteUtils.toHexString(decrypt)); 16.}* 실행 결과
원문 : 68656c6c6f313233
암호 : ad44691609cb1e017378631303581279
복호 : 68656c6c6f313233
4. AES 암호화/복호화 해보기
- DES와 별반 차이 없다. 키 크기가 128비트인것을 제외하면 말이다.
01.public static void main(String[] args) throws Exception { 02. Key key = generateKey("AES", ByteUtils.toBytes("696d697373796f7568616e6765656e61", 16)); 03. String transformation = "AES/ECB/PKCS5Padding"; 04. Cipher cipher = Cipher.getInstance(transformation); 05. cipher.init(Cipher.ENCRYPT_MODE, key); 06. 07. String str = "hello123"; 08. byte[] plain = str.getBytes(); 09. byte[] encrypt = cipher.doFinal(plain); 10. System.out.println("원문 : " + ByteUtils.toHexString(plain)); 11. System.out.println("암호 : " + ByteUtils.toHexString(encrypt)); 12. 13. cipher.init(Cipher.DECRYPT_MODE, key); 14. byte[] decrypt = cipher.doFinal(encrypt); 15. System.out.println("복호 : " + ByteUtils.toHexString(decrypt)); 16.}* 실행 결과
원문 : 68656c6c6f313233
암호 : d5c5e1ffb734b610679f36c0e535fe39
복호 : 68656c6c6f313233
5. IV 사용하기.
- 블록 암호의 운용 모드(Block engine modes of operation)가 CBC/OFB/CFB를 사용할 경우에는 Initialization Vector(IV)를 설정해줘야한다. 왜냐면 사용하기 때문이다. AES 암호화/복호화 코드에서 운용 모드가 CBC로 변경해보자.
01.public static void main(String[] args) throws Exception { 02. Key key = generateKey("AES", ByteUtils.toBytes("696d697373796f7568616e6765656e61", 16)); 03. String transformation = "AES/CBC/PKCS5Padding"; 04. Cipher cipher = Cipher.getInstance(transformation); 05. cipher.init(Cipher.ENCRYPT_MODE, key); 06. 07. String str = "hello123"; 08. byte[] plain = str.getBytes(); 09. byte[] encrypt = cipher.doFinal(plain); 10. System.out.println("원문 : " + ByteUtils.toHexString(plain)); 11. System.out.println("암호 : " + ByteUtils.toHexString(encrypt)); 12. 13. cipher.init(Cipher.DECRYPT_MODE, key); 14. byte[] decrypt = cipher.doFinal(encrypt); 15. System.out.println("복호 : " + ByteUtils.toHexString(decrypt)); 16.}* 실행 결과 원문 : 68656c6c6f313233
암호 : 92e4fa9add0d4d5a07954207890e5b5c
Exception in thread "main" java.security.InvalidAlgorithmParameterException: Parameters missing
...생략...
실행해보면 암호화는 되는데, 복호화도중 파라메터가 없다고 에러가 발생한다. 예상한데로라면 암호화할때도 에러가 나야하는데, 불행히도 암호화는 정상적으로 작동한다. 왜냐면 암호화할때는 IV를 지정해주지 않으면, 자동적으로 랜덤 IV를 만들어서 사용해버린다.
정말인지 테스트해보자.
01.public static void main(String[] args) throws Exception { 02. Key key = generateKey("AES", ByteUtils.toBytes("696d697373796f7568616e6765656e61", 16)); 03. String transformation = "AES/CBC/PKCS5Padding"; 04. Cipher cipher = Cipher.getInstance(transformation); 05. cipher.init(Cipher.ENCRYPT_MODE, key); 06. 07. String str = "hello123"; 08. byte[] plain = str.getBytes(); 09. byte[] encrypt = cipher.doFinal(plain); 10. System.out.println("원문 : " + ByteUtils.toHexString(plain)); 11. System.out.println("암호 : " + ByteUtils.toHexString(encrypt)); 12. 13. cipher.init(Cipher.DECRYPT_MODE, key, new IvParameterSpec(cipher.getIV())); 14. byte[] decrypt = cipher.doFinal(encrypt); 15. System.out.println("복호 : " + ByteUtils.toHexString(decrypt)); 16.}* 실행 결과
원문 : 68656c6c6f313233
암호 : 26c7d1d26c142de0a3b82f7e8f90860a
복호 : 68656c6c6f313233
new IvParameterSpec(cipher.getIV())을 이용해서 자동 생성된 IV를 초기화 파라메터를 넘겨주니 정상 작동한다.
실제 사용할때는 암호화 복호화가 따로(?) 작동하니 이렇게 구현하는건 불가능할것이다. IV의 크기는 블럭크기와 동일하므로 키처럼 생성해서 잘 관리하면 되겠다.
01.public static void main(String[] args) throws Exception { 02. Key key = generateKey("AES", ByteUtils.toBytes("696d697373796f7568616e6765656e61", 16)); 03. byte[] iv = ByteUtils.toBytes("26c7d1d26c142de0a3b82f7e8f90860a", 16); 04. String transformation = "AES/CBC/PKCS5Padding"; 05. IvParameterSpec ivParameterSpec = new IvParameterSpec(iv); 06. Cipher cipher = Cipher.getInstance(transformation); 07. cipher.init(Cipher.ENCRYPT_MODE, key, ivParameterSpec); 08. 09. String str = "hello123"; 10. byte[] plain = str.getBytes(); 11. byte[] encrypt = cipher.doFinal(plain); 12. System.out.println("원문 : " + ByteUtils.toHexString(plain)); 13. System.out.println("암호 : " + ByteUtils.toHexString(encrypt)); 14. 15. cipher.init(Cipher.DECRYPT_MODE, key, ivParameterSpec); 16. byte[] decrypt = cipher.doFinal(encrypt); 17. System.out.println("복호 : " + ByteUtils.toHexString(decrypt)); 18.}* 실행 결과
원문 : 68656c6c6f313233
암호 : 1876c3ae98760ccf1821ea46fc9ce761
복호 : 68656c6c6f313233
6. 파일을 AES 암호화/복호화 해보기
- 이번에 파일을 읽어와서 암호화/복호화를 해보자. JavaIO를 다룰 수 있으면 간단히 구현할 수 있을것이다.
01.public static void main(String[] args) throws Exception { 02. 03. Key key = generateKey("AES", ByteUtils.toBytes("696d697373796f7568616e6765656e61", 16)); 04. String transformation = "AES/ECB/PKCS5Padding"; 05. Cipher cipher = Cipher.getInstance(transformation); 06. cipher.init(Cipher.ENCRYPT_MODE, key); 07. File plainFile = new File("c:/plain.txt"); 08. File encryptFile = new File("c:/encrypt.txt"); 09. File decryptFile = new File("c:/decrypt.txt"); 10. 11. BufferedInputStream input = null; 12. BufferedOutputStream output = null; 13. try { 14. input = new BufferedInputStream(new FileInputStream(plainFile)); 15. output = new BufferedOutputStream(new FileOutputStream(encryptFile)); 16. 17. int read = 0; 18. byte[] inBuf = new byte[1024]; 19. byte[] outBuf = null; 20. while ((read = input.read(inBuf)) != -1) { 21. outBuf = cipher.update(inBuf, 0, read); 22. if (outBuf != null) { 23. output.write(outBuf); 24. } 25. } 26. outBuf = cipher.doFinal(); 27. if (outBuf != null) { 28. output.write(outBuf); 29. } 30. } finally { 31. if (output != null) try {output.close();} catch(IOException ie) {} 32. if (input != null) try {input.close();} catch(IOException ie) {} 33. } 34. 35. cipher.init(Cipher.DECRYPT_MODE, key); 36. try { 37. input = new BufferedInputStream(new FileInputStream(encryptFile)); 38. output = new BufferedOutputStream(new FileOutputStream(decryptFile)); 39. 40. int read = 0; 41. byte[] inBuf = new byte[1024]; 42. byte[] outBuf = null; 43. while ((read = input.read(inBuf)) != -1) { 44. outBuf = cipher.update(inBuf, 0, read); 45. if (outBuf != null) { 46. output.write(outBuf); 47. } 48. } 49. outBuf = cipher.doFinal(); 50. if (outBuf != null) { 51. output.write(outBuf); 52. } 53. } finally { 54. if (output != null) try {output.close();} catch(IOException ie) {} 55. if (input != null) try {input.close();} catch(IOException ie) {} 56. } 57.}"plain.txt"란 파일을 만들어 놓고 실행하면, "encrypt.txt"와 "decrypt.txt" 파일이 생성될것이다. 제대로 암호화 복호화되었는지 비교해보자.
7. 비밀번호 암호화
- 대부분의 사이트에서 비밀번호를 암호화한다.(불행히도 안하는곳도 많다.) 위에서 배운 블럭암호화 알고리즘으로 암호화를 한다면, 사이트 관리자들은 비밀번호를 다 알 수 있을것이다. (키를 해당 사이트에서 관리하므로, 키를 알면 복호화가 가능하다.) 정말 기분 나쁘다. 타인이 나의 비밀번호를 안다는것은... 그러면 관리자들도 모르게 암호화를 할려면 어떻게 해야할까?
아주 간단하다. 암호화에 사용하는 키 자체를 평문 즉, 비밀번호로 사용하면 된다. 아래 처럼 구현하면 본인만 알 수가 있는것이다. 암호화 할려는 비밀번호 자체가 두 역활을 동시에 하는것이다. 한번 구현해보자.
01.public static void main(String[] args) throws Exception { 02. String password = "mypassword"; 03. 04. byte[] passwordBytes = password.getBytes(); 05. int len = passwordBytes.length; 06. byte[] keyBytes = new byte[16]; 07. if (len >= 16) { 08. System.arraycopy(passwordBytes, 0, keyBytes, 0, 16); 09. } else { 10. System.arraycopy(passwordBytes, 0, keyBytes, 0, len); 11. for (int i = 0; i < (16 - len); i++) { 12. keyBytes[len + i] = passwordBytes[i % len]; 13. } 14. } 15. 16. Key key = generateKey("AES", keyBytes); 17. String transformation = "AES/ECB/PKCS5Padding"; 18. Cipher cipher = Cipher.getInstance(transformation); 19. cipher.init(Cipher.ENCRYPT_MODE, key); 20. 21. 22. byte[] plain = password.getBytes(); 23. byte[] encrypt = cipher.doFinal(plain); 24. System.out.println("원문 : " + ByteUtils.toHexString(plain)); 25. System.out.println("암호 : " + ByteUtils.toHexString(encrypt)); 26. 27. cipher.init(Cipher.DECRYPT_MODE, key); 28. byte[] decrypt = cipher.doFinal(encrypt); 29. System.out.println("복호 : " + ByteUtils.toHexString(decrypt)); 30.}키는 패딩이 안되기 때문에 자체적으로 길이를 맞춰줘야한다. 여기서는 16바이트보다 크면 자르고, 16바이트보다 작으면 입력받는 비밀번호 문자를 반복해서 뒤에 붙여두는식으로 구현하였다.
이런 방식이 귀찮다면 블럭 암호화 방법 대신, MD5나 SHA1으로 메시지 해쉬값을 저장해서 그 값을 비교해도 된다. (이 방식은 복호화가 안된다.) my-sql password() 함수가 SHA1을 이용하는데, 다음번에 알아보도록 하자.
|
<?xml:namespace prefix = o ns = "urn:schemas-microsoft-com:office:office" />
|
Java 기반 DES 암호화를 찾던 중 정리한 소스
1. Key는 관리차원에서 고정키로 사용 (키발급 안함)
2. DES, TripleDES 모두 가능
3. TripleDES로 사용하는 경우 Key Size는 24 바이트로 지정 (이하시 에러)
| package system.user.MD5; import java.security.*; import javax.crypto.*; import javax.crypto.spec.DESKeySpec; import javax.crypto.spec.DESedeKeySpec; public class DES { public static void main(String[] args) throws Exception { String text = "java12345"; String enen = encrypt(text); String dede = decrypt(enen); System.out.println("\nOrigin key: " + key()); System.out.println("\nOrigin text: " + text); System.out.println("\nEncrypted text: " + enen); System.out.println("\nDecrypted text: " + dede); } /** * 고정키 정보 * @return */ public static String key() { return "ab_booktv_abcd09"; //return "ab_booktv_abcd0912345678"; } /** * 키값 * 24바이트인 경우 TripleDES 아니면 DES * @return * @throws Exception */ public static Key getKey() throws Exception { return (key().length() == 24) ? getKey2(key()) : getKey1(key()); } /** * 지정된 비밀키를 가지고 오는 메서드 (DES) * require Key Size : 16 bytes * * @return Key 비밀키 클래스 * @exception Exception */ public static Key getKey1(String keyValue) throws Exception { DESKeySpec desKeySpec = new DESKeySpec(keyValue.getBytes()); SecretKeyFactory keyFactory = SecretKeyFactory.getInstance("DES"); Key key = keyFactory.generateSecret(desKeySpec); return key; } /** * 지정된 비밀키를 가지고 오는 메서드 (TripleDES) * require Key Size : 24 bytes * @return * @throws Exception */ public static Key getKey2(String keyValue) throws Exception { DESedeKeySpec desKeySpec = new DESedeKeySpec(keyValue.getBytes()); SecretKeyFactory keyFactory = SecretKeyFactory.getInstance("DESede"); Key key = keyFactory.generateSecret(desKeySpec); return key; } /** * 문자열 대칭 암호화 * * @param ID * 비밀키 암호화를 희망하는 문자열 * @return String 암호화된 ID * @exception Exception */ public static String encrypt(String ID) throws Exception { if (ID == null || ID.length() == 0) return ""; String instance = (key().length() == 24) ? "DESede/ECB/PKCS5Padding" : "DES/ECB/PKCS5Padding"; javax.crypto.Cipher cipher = javax.crypto.Cipher.getInstance(instance); cipher.init(javax.crypto.Cipher.ENCRYPT_MODE, getKey()); String amalgam = ID; byte[] inputBytes1 = amalgam.getBytes("UTF8"); byte[] outputBytes1 = cipher.doFinal(inputBytes1); sun.misc.BASE64Encoder encoder = new sun.misc.BASE64Encoder(); String outputStr1 = encoder.encode(outputBytes1); return outputStr1; } /** * 문자열 대칭 복호화 * * @param codedID * 비밀키 복호화를 희망하는 문자열 * @return String 복호화된 ID * @exception Exception */ public static String decrypt(String codedID) throws Exception { if (codedID == null || codedID.length() == 0) return ""; String instance = (key().length() == 24) ? "DESede/ECB/PKCS5Padding" : "DES/ECB/PKCS5Padding"; javax.crypto.Cipher cipher = javax.crypto.Cipher.getInstance(instance); cipher.init(javax.crypto.Cipher.DECRYPT_MODE, getKey()); sun.misc.BASE64Decoder decoder = new sun.misc.BASE64Decoder(); byte[] inputBytes1 = decoder.decodeBuffer(codedID); byte[] outputBytes2 = cipher.doFinal(inputBytes1); String strResult = new String(outputBytes2, "UTF8"); return strResult; } } |
결과
==================================
Origin key: ab_booktv_abcd09
Origin text: java12345
Encrypted text: 3nAuFnFNtxDWBHOqueEpdA==
Decrypted text: java12345
1. JMeter의 소개
JMeter는 Apache Jakarta 프로젝트의 일환으로 만들어진 테스트 기능과 퍼포먼스를 측정하는 애플리케이션이다. 이 애플리케이션 100% 순수 자바로 작성되었으며 원래 웹 애플리케이션을 위해 디자인되고 사용되었으나 현재는 다른 기능의 테스트를 위해 확장되고 있다.
JMeter는 static, dynamic 한 모든 자원(파일, 서블릿, perl script, java object, database and query, ftp, soap 등)에 대해 퍼포먼스를 테스트할 수 있다. 이러한 테스트 결과로 분석결과를 그래픽으로 표시해주는 기능과 스크립트 객체 등에 대해 과도한 동시 처리 부하가 가능하다.
Apache Jmeter는 다음 사이트에서 얻을 수 있다.
http://jakarta.apache.org/jmeter/
JMeter에 대한 추가 정보는 위 사이트에서 얻을 수 있다. 한데 위 사이트는 영어로 구성되어 있기 때문에 조금 빈약하더라도 한국어로 된 정보는 자카르타 서울 프로젝트에서 얻을 수 있다.
http://jakarta.apache-korea.org
2. JMeter를 얻고 설치하기
JMeter를 설치 하기 위해서 우선 Jakarta 의 JMeter 사이트에 접속한다. 다음 그림들은 Jakarta 메인 사이트와 JMeter 사이트를 보여준다.
[그림 2-1] Jakarta 사이트
[그림 2-2] Jakarta JMeter 사이트
JMeter를 다운로드 받기 위해선 화면 왼쪽의 Download Binary 링크를 통해 들어가면 다운로드 받을 수 있다.
[그림 2-3] Jakarta 다운로드 링크 페이지
Jakarta 프로젝트는 다수의 서브 프로젝트들로 이뤄져 있기 때문에 실제적인 다운로드는 Downloads 섹션의 Jmeter를 클릭하면 다운로드 받을 수 있게 된다. [그림 2-3]은 그 화면을 나타낸다.
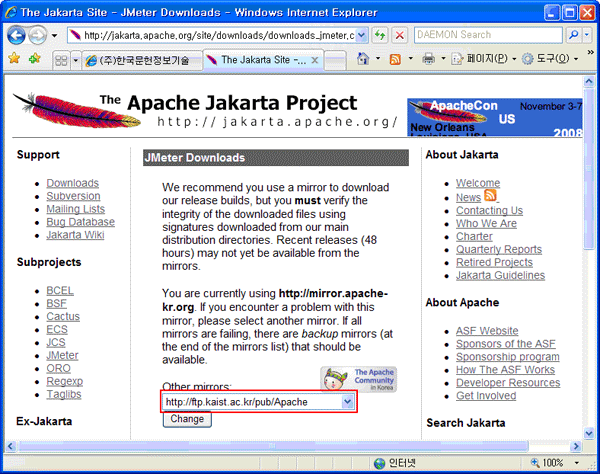
[그림 2-4] Mirror 페이지
[그림 2-3]에서 JMeter 를 클릭하면 곧 바로 다운로드를 시작하지는 않고 어디서 다운로드 받을지 물어오게 된다. 본 문서에서는 미러 사이트로 한국 아파치 사용자 모임을 선택했다. [그림 2-4]에 보이는 빨간 박스를 클릭하면 미러 사이트가 나타나게 된다. 미러 사이트를 선택했다면 Change 버튼을 눌러 미러 페이지를 변경시킨다.
미러 사이트는 다수가 존재하는데 다운로드 속도가 느릴 경우 바꿔가며 시도해본다. 일반적으로 기본적으로 선택되는 미러 사이트를 이용해도 된다.
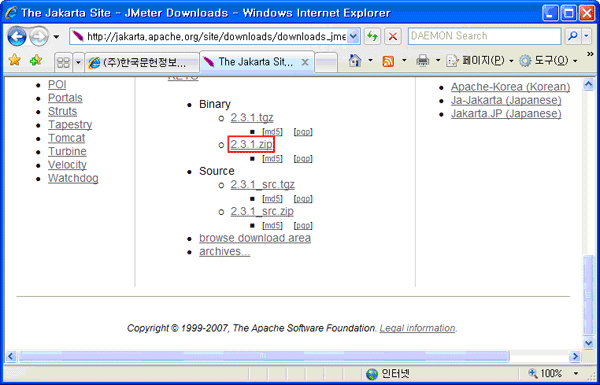
[그림 2-5] JMeter 다운로드 링크
[그림 2-4]의 화면에서 미러 사이트를 변경하지 않았거나 변경한 경우 화면 스크롤을 내리면 빨간박스로 그려진 부분 2.3.1.zip 부분을 볼 수 있다. 이 부분을 클릭하면 본격적인 다운로드 윈도우를 볼 수 있다.
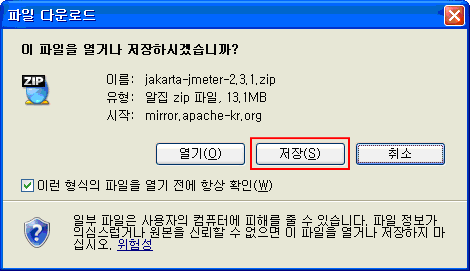
[그림 2-6] 파일 저장 윈도우
[그림 2-6]에서 보여지는 윈도우는 파일을 어디에 저장할 것인지를 물어오는 화면이다. 본문에서는 바탕 화면에 저장하였다.

[그림 2-7] 바탕화면에 저장된 JMeter 파일
[그림 2-6]에서 바탕 화면에 저장된 파일은 [그림 2-7]과 같다.
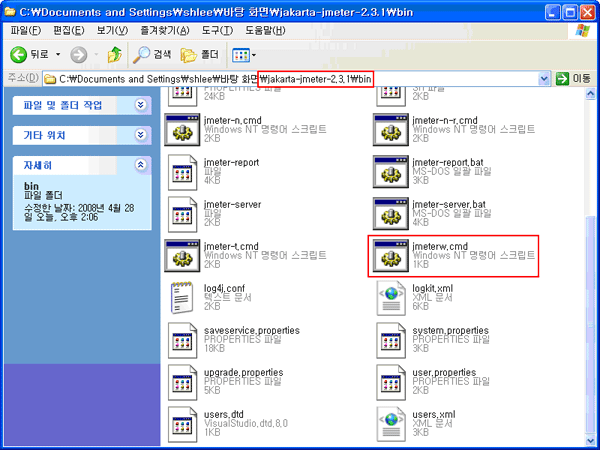
[그림 2-8] JMeter 실행 파일
JMeter는 Java Application 이기 때문에 별도의 설치 프로그램을 필요로 하지 않는다. 본문에서는 압축파일을 선택한 후 바탕 화면 폴더에 압축 내용을 별도의 폴더 생성 과정 없이 풀었다. 이렇게 푸는 이유는 JMeter 압축파일이 별도의 상위 폴더를 가지고 있기 때문이다. [그림 2-8]은 그런 화면을 나타낸다.
JMeter의 실행은 [그림 2-8]에 보이는 것처럼 jmeterw.cmd 파일을 더블 클릭하면 실행한다.
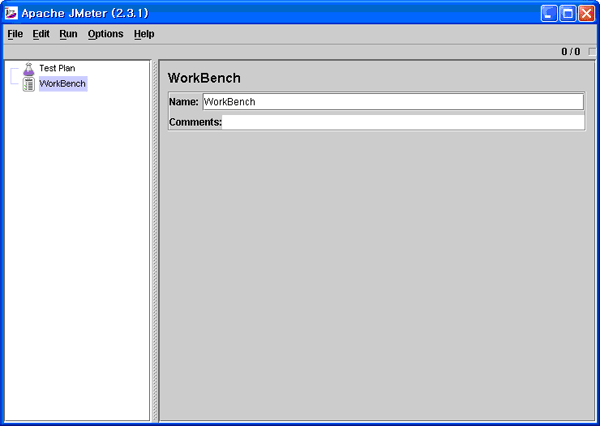
[그림 2-9] JMeter의 실행 화면
3. JMeter 기본 과정
JMeter는 테스트 환경에 있어 상위 항목으로 WorkBench와 Test Plan를 두고 있다. 이 상위 항목을 다른 이름으로 노드라고 표현한다. 노드라는 단어는 Tree에서 비롯되었는데 JMeter는 각각의 element를 계층적으로 관리 하기 위해서 Tree 구조를 사용한다. JMeter는 테스트 앞서 Test Plan을 먼저 작성하게 된다. Test Plan은 한국어로 풀어 쓰면 테스트 계획인데 JMeter의 모든 Test는 이 Test Plan을 먼저 세워야 한다.
Test Plan + HTTP TestWorkBench[모식도 3-1] JMeter 모식도
[모식도 3-1]은 위에서 설명한 구조를 간략히 그려내 본 것이다. JMeter는 Test Plan과 WorkBench 아래에 놓이는 것을 가리켜 Element라고 한다. 한국어로는 요소라는 말이 적절하겠지만 이해를 돕기 위해 원어로 표기한다. Element는 여러 종류가 있는데 Test Plan에 바로 올 수 있는 Element는 다음과 같은 것들이 있다.

[그림 3-1] Test Plan 에 추가될 수 있는 element
[그림 3-1]은 Test Plan 노드 아래 추가될 수 있는 element를 나타내고 있는데 기본 테스트를 하기 위해선 Thread Group과 Listener 의 추가가 우선적이다. Thread Group는 테스트의 가장 기본적인 요소로써 Test Plan 노드 아래 몇 개든 올 수 있다. Thread Group은 논리적인 모습으로 표현하면 테스트 클라이언트들의 묶음이라고 보는 표현이 타당하다.
JMeter는 단지 Thread Group을 구성하는 것만으로 결과를 볼 수 없다. 이 뚱딴지 같은 이야기는 JMeter가 결과를 보기 위한 또 다른 구성 요소를 필요로 한다는 것이다. JMeter는 테스트 결과를 다양한 형태로 볼 수 있도록 다음과 같은 구성 요소를 지원한다.

[그림 3-2] Listener의 구성 요소
[그림 3-2]에 보이는 element 중 가장 많이 사용되는 요소는 Graph Results, Summary Report, View Results in Table, View Results Tree다.
다시 앞으로 돌아가서 Thread Group은 테스트에 있어서 기본적인 단위가 된다고 했다. 이제 Thread Group 아래 다른 element를 추가할 필요가 있다.
Test Plan 노드에 Thread Group을 추가한 후 마우스 오른쪽 클릭을 통해 보면 [그림 3-1]에서 보던 것과 비슷한 화면이 보이는데 하나 더 추가된 element 그룹이 존재한다.
[그림 3-3] Thread Group에서의 마우스 오른쪽 팝업
[그림 3-3]에는 Sampler 그룹이 보이는데 바로 이 그룹이 JMeter 테스트에 있어서 실제로 부하를 보내는 실제적인 주체가 들어 있는 그룹이다. Sampler는 다양한 element가 들어가 있는데 대표적으로 다음과 같은 sampler 항목을 들어볼 수 있다.

[그림 3-4] 많이 쓰이는 Sampler
Sampler는 위의 그림에 보이는 것보다 더 많지만 기본적인 기능 테스트 및 웹 애플리케이션 테스트에는 [그림 3-4]에 있는 Sampler가 더 많이 쓰인다.
본문에서는 HTTP Request Sampler에 대해서만 집중적으로 다룰텐데 다른 Sampler에 대해선 다른 기회가 주어진다면 하나씩 파보는 기회를 가져보도록 하겠다.
Thread Group에는 Sampler 뿐 아니라 다른 element들도 추가가 가능한데 이들 element에 대해서도 다른 기회가 주어졌을 때 파보는 기회를 가져보겠다.
자 이제까지 설명한 것은 JMeter에서 스트레스 테스트를 하기 위한 기본 구조를 설명하였다. [그림 3-5]는 지금까지 설명한 구조를 실제로 구현한 JMeter의 Test Plan 의 모습이다.
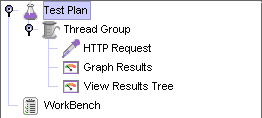
[그림 3-5] 간단한 Test를 위한 Test Plan
다음 섹션에서는 [그림 3-5]를 기반으로 한 Simple한 Test를 진행해보겠다.
4. JMeter를 사용한 Simple Test
지금까지 간략히 JMeter의 테스트 계획에 대해서 알아보았는데 본 섹션에서는 앞에서 다루었던 Test Plan에 실제 숨을 불어넣어 본다.
본문에서는 저자가 운영진으로 활동하고 있는 한국 아파치 사용자 모임 사이트를 대상으로 삼았다. 우선 HTTP Request 노드를 선택하면 JMeter 의 오른쪽 화면이 바뀌면서 [그림 4-1]처럼 나타나게 된다.
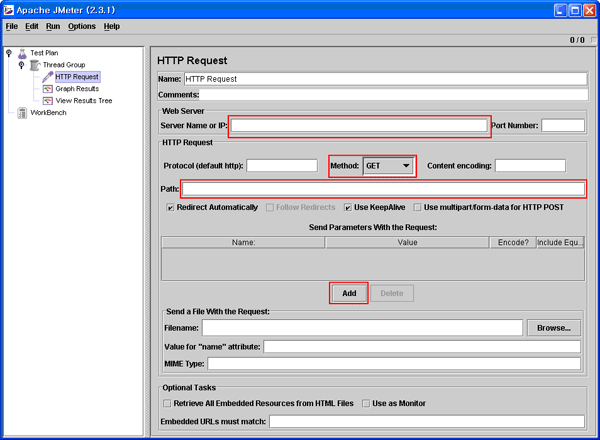
[그림 4-1] HTTP Request 선택
[그림 4-1]에는 빨간 박스가 다수 보이는데 이 박스 안의 내용을 입력하거나 선택함으로서 테스트 정보를 입력한다.
첫번째 입력할 정보는 테스트할 서버의 IP 또는 URL을 입력하는데 URL은 프로토콜 정보를 제외한 순수 주소만 적는다. 다음과 같은 URL이 테스트할 정보라고 보고 Server Name을 분리하자.
http://www.apache-kr.org/www/board.php?cmd=retrieveContent&board_cd=techtalk&rg_d=20080410&rg_seq_n=1&pageID=1&search_gb=&fr_rg_d=&to_rg_d=&searchstring=
Server Name은 www.apache-kr.org가 되어야 한다.
두번째 입력하고 선택할 정보는 Method와 Path인데 이 정보는 실제로 테스트할 URL 정보가 들어간다.
Path는 실제 테스트할 URL을 말하는데 / 로부터 시작하고 인자가 시작되기 전까지의 정보를 적는다. 앞에서 언급된 URL을 기준으로 path는 아래와 같이 분리된다.
/www/board.php위에서 나타난 파일이 어떤 인자를 받는다면 그 인자 방식을 Method에서 선택해준다. 여러 Method를 사용할 수 있지만 웹 애플리케이션은 일반적으로 GET 방식과 POST 방식을 사용한다. 예제로 쓰는 URL은 모든 정보를 GET 방식으로 던진다. 따라서 Method는 GET으로 지정한다. 물론 인자를 받지 않는다면 Parameter 정보를 입력하지 않아도 된다.
HTTP Request 노드의 Method 기본값은 GET이기 때문에 혹시 GET이 아니면 수정해주도록 한다. Add 버튼을 클릭하면 파라메터 정보를 입력받게 된다.
본문에서는 Add 버튼을 5번 눌러 파라메터 입력을 5개 만들었다. 입력할 파라메터는 다음 목록과 같다.
cmdboard_cdrg_drg_seq_npageID서버 정보 및 파라메터 정보를 모두 입력한 화면은 [그림 4-2]와 같다.
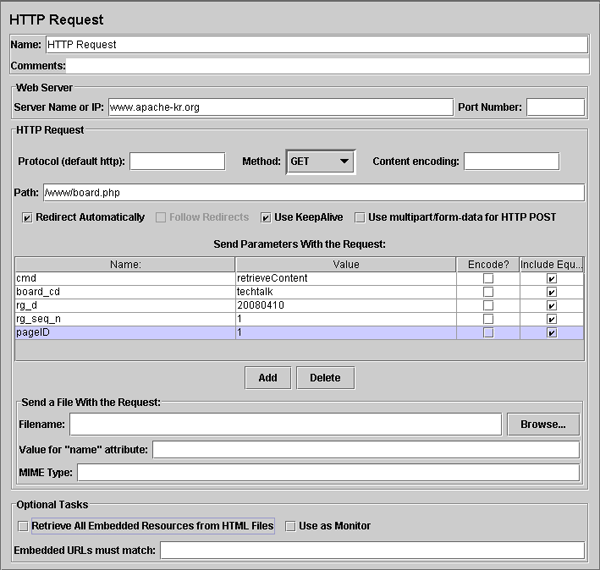
[그림 4-2] 테스트 정보를 모두 입력한 화면
HTTP Request 정보를 모두 입력했다면 Thread Group에 관한 설정을 할 차례다. JMeter의 왼쪽 트리에서 Thread Group 노드를 선택하면 [그림 4-3]과 같은 화면이 나타난다.
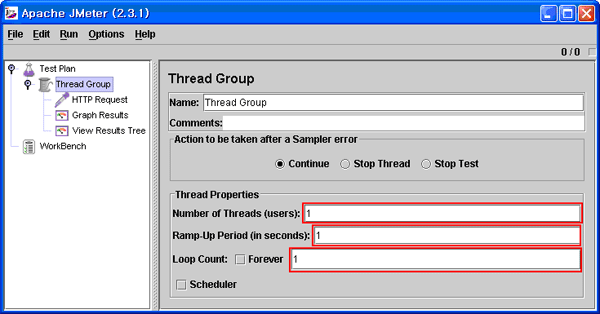
[그림 4-3] Thread Group 정보 입력
[그림 4-3]에 보이는 Thread Group 정보는 몇가지 예의 주시해서 입력해야 할 정보가 있다.
첫번째 박스는 몇 명의 사용자로 동시 접속 부하를 줄것인지에 대한 것인데 사용자명을 높게 지정할수록 서버의 부하 테스트도 더 커진다.
두번째 박스는 한명의 사용자가 접속자가 서버로 부하를 주러 떠나고 다른 사용자가 부하를 주러 떠날 때 사용자간의 접속 시간을 지정한다. JMeter 문서에는 쓰레드의 생성 주기를 나타낸다고 하지만 이해를 돕기 위해서 사용자간의 접속 시간으로 보면 된다.
세번째 박스는 Thread Group에 속해있는 Sampler들을 몇번 보낼 것인지 지정한다. 이해가 어렵다면 HTTP Request에서 지정했던 URL을 Loop Count 에 지정한 숫자만큼 다시 서버에 요청을 한다고 이해하면 된다. 만약 Forever 박스를 체크했다면 JMeter 실행자는 JMeter를 수동적으로 정지시켜줘야 한다.
본문에서는 Number of Threads(users)를 10명으로 Loop Count는 3으로 수정하였다. 이 숫자나 양은 테스트 부하에 따라 적절하게 조정해주면 된다.
이제 부하 테스트를 해볼 차례다. 부하 테스트는 메뉴에서 Run > Start를 선택하거나 Ctrl + R 키를 누르면 Test Plan을 저장할 것인지 묻게 되고 아니오(N)을 누르면 테스트를 시작한다. 만약 Test Plan이 저장되어 있다면 바로 부하 테스트를 시작하게 된다.
[그림 4-4] 테스트 계획을 저장하시겠습니까?
부하가 진행되는 중에는 [그림 4-5]에 있는 네모 박스에 녹색불이 들어오면서 테스트를 시작한다.

[그림 4-5] 부하가 진행중인 표시
부하 테스트가 끝나면 JMeter의 왼쪽 트리에서 View Results Tree를 선택하면 오른쪽 화면이 [그림 4-6] 처럼 바뀌게 된다.
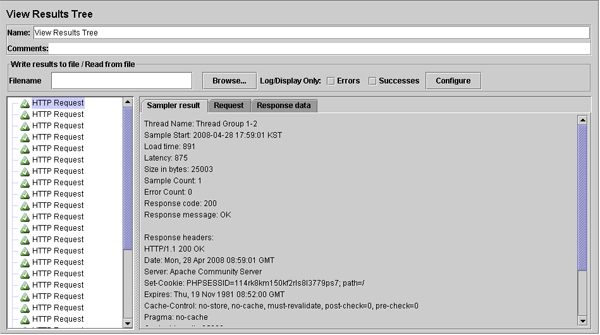
[그림 4-6] View Results Tree
[그림 4-6]과 같이 테스트한 결과가 출력되었다면 테스트는 정상적으로 이루어진 것이다. 하지만 종종 화면 좌측에 보이는 초록색의 삼각 아이콘 모습이 나타나지 않으면 네트워크 연결 오류나 서버측 오류로 인해 테스트할 없는 상황으로 본다.
다음 [그림 4-7]은 Graph Results 노드를 선택한 결과이다.
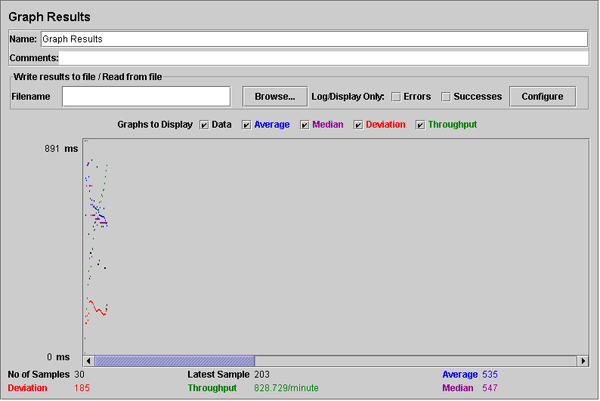
[그림 4-7] Graph 결과로 표시된 부하 테스트
5. JMeter를 사용한 실제 전략
본 섹션에서는 JMeter를 사용해 실제로 로그인하고 로그인한 정보를 바탕으로 접근 가능한 URL에 접근해 부하 테스트를 진행해보겠다.
본문에서는 테스트를 설명하기 위해서 daum 에 로그인하고 저자가 카페지기로 있는 사이트에 가서 특정글에 대한 요청을 서버에게 던져서 정상적으로 글을 가져오는지 확인해보겠다.
우선 다음과 같이 Test Plan 노드를 추가한다.
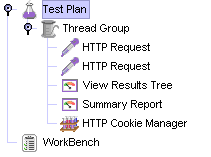
[그림 5-1] Daum의 Café에 접속하기 위해 글을 가져오기 위한 Test Plan
[그림 5-1]과 같이 Test Plan을 만들면 되는데 가만 보면 못 보던 요소가 하나 존재한다. 바로 HTTP Cookie Manager인데 Cookie Manager는 JMeter 2.0.3 부터 새로이 추가된 element다.
이 element의 추가는 [그림 5-2]에서 보이는 것과 같이 추가한다.

[그림 5-2] HTTP Cookie Manager 추가하기
Cookie Manager는 Thread Group이나 Test Plan 노드에 추가해도 되는데 Test Plan 노드에 추가하는 경우는 여러 Thread Group이 모두 로그인 페이지를 요구하는 경우 유용하게 사용할 수 있다.
반대로 특정 Thread Group에서만 로그인 페이지를 요구하는 경우 Thread Group에만 추가하면 된다.
그리고 HTTP Request Sampler를 총 2개 추가한다.
HTTP Request Sampler는 다음 [그림 5-3]과 같이 설정한다.
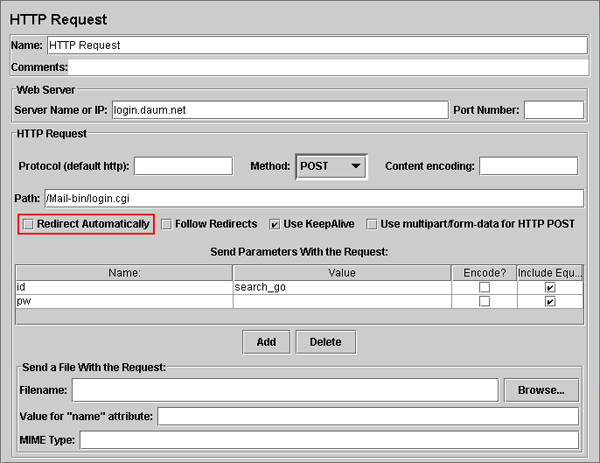
[그림 5-3] HTTP Request 1
첫번째 HTTP Request는 Daum에 로그인 요청을 하는 Sampler이다. [그림 5-3]에 보이는 요소에 대해서는 섹션 4에서 다루었기 때문에 섹션 4와 비교했을 때 다른 것만 알아보기로 한다.
[그림 5-3]에는 빨간 박스로 강조되어진 부분이 있는데 이 부분은 JMeter에서 요청을 한후 자동으로 주소를 변경할지를 설정하는데 일부 사이트의 경우 이 옵션이 켜져 있을 경우 문제가 된다. 때문에 로그인하는 요청의 경우 옵션은 해제해주는게 좋다. 그리고 Follow Redirects 옵션을 켜주는게 좋다. Follow Redirects 옵션은 웹 사이트의 Redirect 액션을 허용한다.
[그림 5-4]는 실제 게시물에 접근하는 요청이다. 이때 접근하는 URL은 미리 페이지 등록정보를 통해 확인한 URL을 이용한다.
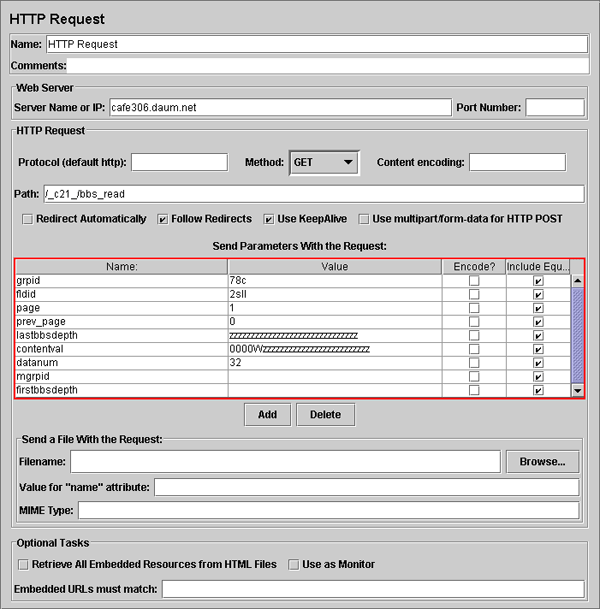
[그림 5-4] HTTP Request 2
[그림 5-4]는 게시물에 접근하는 요청이다. 빨간 박스로 강조된 부분은 Path에 인자로 넘겨지는 부분인데 이와 같이 URL에 접근에 있어서 파라메터를 요구하는 경우는 1개씩 인자를 생성해주어야 한다.
이제 요청 결과를 알아보기 위해 Test Plan을 실행한다. Test Plan의 실행은 Run > Start 메뉴를 선택하거나 Ctrl + R 키를 누른다.
그럼 [그림 5-5]와 같이 Test Plan을 저장할 것이냐고 물어오는데 본문은 테스트이므로 아니오를 눌러 저장하지 않는다.
[그림 5-5] Test Plan을 저장할것입니까?
스트레스 테스트가 끝나면 JMeter의 왼쪽 트리에서 View Results Tree 노드를 선택한다.

[그림 5-6] View Results Tree 노드 선택
이제 JMeter의 화면 오른편에는 [그림 5-7]과 같은 화면이 있는 걸 볼 수 있다.
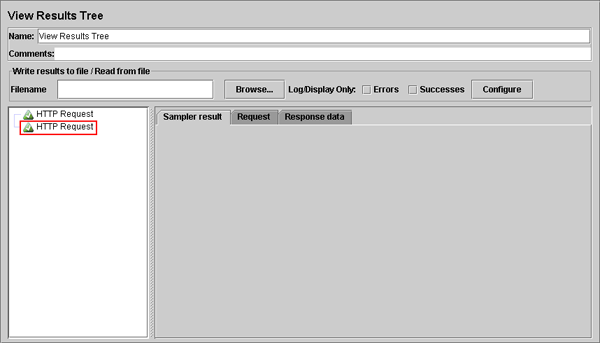
[그림 5-7] View Results Tree 초기 화면
이제 [그림 5-7]에 보이는 항목을 클릭하면 [그림 5-8]과 같이 변경된다.
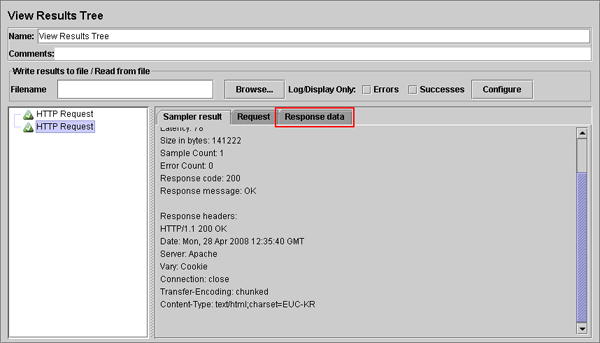
[그림 5-8] 2번째 HTTP Request 클릭 후
[그림 5-8]의 결과를 보면 정상적으로 수행은 된거 같은데 어떤 결과가 왔을지 사뭇 궁금해진다. 결과를 확인하기 위해 [그림 5-8]에 보이는 Response data 탭을 클릭하고 적절하게 위치를 이동하면 아래와 같은 결과를 확인해볼 수 있다.
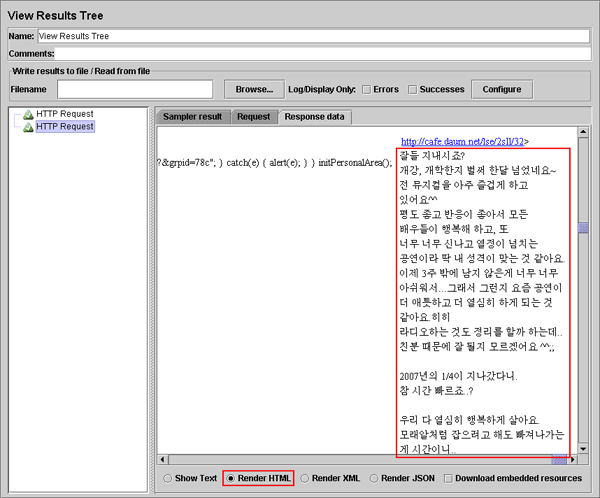
[그림 5-9] 정상적으로 받아온 데이터
[그림 5-9]에 보이는 화면과 같이 데이터를 정상적으로 받아온 것을 확인할 수 있다. 물론 [그림 5-9]에 보이는 것과 같이 보이지 않는다면 [그림 5-9] 하단에 보이는 Render HTML이나 Show Text 라디오 버튼을 선택해야 한다. Render HTML의 경우 일부 웹 사이트는 정상적으로 보여지지 않을 수 있기 때문에 Show Text 라디오 버튼을 선택해서 보는 것이 더 정확하다.
사족으로 [그림 5-9]에 보이는 내용은 가수 이소은씨가 팬카페에 2007년 4월에 게시판에 남겨준 내용이다.
여기까지 잘 따라왔다면 정상적으로 처리가 되어야 하지만 그렇지 않다면 뭔가 이상이 있는 경우이므로 다시한번 확인해보기로 한다.
6. JMeter 로그 분석하기
JMeter로 테스트는 했는데 정작 테스트 결과를 볼 수 없거나 엉뚱한 자료만 가지고 있다면 분석은 못하게 될것이다.
이를 위해서 Listener로 Summary Report element를 추가해주는 것을 권장한다.
섹션 5에서 수행했던 Summary Report를 보면 [그림 6-1]과 같다.
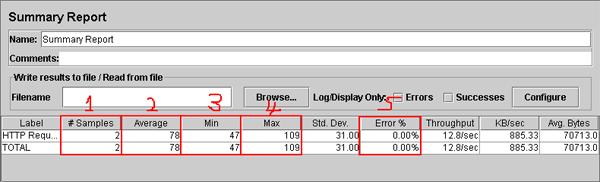
[그림 6-1] Summary Report
[그림 6-1]은 섹션 5에서 수행된 Summary Report인데 눈여겨 봐야 할 컬럼은 총 5개로 위 그림에서 강조되어 있다.
결과 분석을 위해 첫번째 컬럼부터 살펴본다.
- 1번째 컬럼 : 서버에 요청한 횟수
- 2번째 컬럼 : 평균 응답시간(ms단위)
- 3번째 컬럼 : 최소 응답시간(ms단위)
- 4번째 컬럼 : 최대 응답시간(ms단위)
- 5번째 컬럼 : Error율(%단위)
78 milliseconds to seconds
그러면 google이 자동으로 계산해준다.
5번째 컬럼은 서버로의 요청 중에 문제가 있을 경우 에러가 났다거나 한 경우 그 에러율을 퍼센테이지로 표시해준다.
여기서 살펴본 것을 기준으로 간단한 보고서 작성이 가능하겠으나 더 자세한 보고서 작성을 위해 JMeter User Manual을 참조해 다양한 Listener 추가를 통해 다양한 결과 형태를 볼 수 있으므로 꼭 한번씩 참조해서 실행해보는 것을 권장한다.
7. JMeter 활용 전략
JMeter는 그 초기 목적과 달리 다양한 테스트를 위해 확장되고 있으므로 여러 목적으로 사용할 수 있다.
따라서 저자는 JDBC, Java Request, JUnit, FTP 등을 테스트 하기 위해 JMeter 사용을 권장한다.
JMeter의 보다 폭 넓은 활용을 위해서 다음과 같은 사용 전략을 제시한다.
- JDBC 테스트 : DB가 얼마나 부하를 견딜 수 있는지 알고 싶다
- Java Request 테스트 : 순수 자바 애플리케이션을 만들고 있는데 별도의 테스트 툴이 없어서 힘들다.
- JUnit 테스트 : 애플리케이션 테스트를 위해 Junit Test Case를 만들었는데 JMeter로 대신 실행해서 JUnit을 부하 테스트 하는데 사용하고 싶다.
- FTP 테스트 : FTP 서버를 구축했는데 얼마나 접속했을 때 다운되는지 알고 싶다(실제 이렇게 할 사람이 있는지 모르겠다)
JAAS(Java Authentication and Authorization Service) 개요
JAAS(Java Authentication and Authorization Service) 개요
JAAS는 클라이언트 및 서버 시스템을 보호하기 위한 유연하고 확장성 있는 자바 인증 및 권한 부여 서비스를 제공하는 표준 API 입니다.
JAAS는 JDK 1.3에서는 선택적인 패키지로 소개되었으며, J2SE 1.4 부터 표준 확장 API(javax.security.auth)로 배포되고 있습니다.
JAAS는 플러그 가능한 구조로 되어 있어 자바 용용 프로그램이 JAAS 구현 기술에 관계없이 구현할 수 있도록 지원합니다. 즉, 응용 프로그램 개발자는 제공되는 SPI를 이용하여 JAAS 구현 부분과 인터페이스를 하고 구현 부분은 설정 파일을 통하여 구동 시 결정됩니다.
따라서, JAAS 기반으로 개발된 응용 프로그램은 소스 변경 및 재 컴파일 없이 설정 파일을 변경함으로써 JAAS 구현 메커니즘을 변경할 수 있습니다.
JAAS는 다음과 같은 패턴 및 프레임워크에서 많은 장점들을 받아들였습니다.
- PAM (Pluggable Authentication Module) – Stackable Feature
- 2-PC (Two-phase commit) - Transactional View
- Policy, Permission – J2SE security package
- Subject – Java security framework
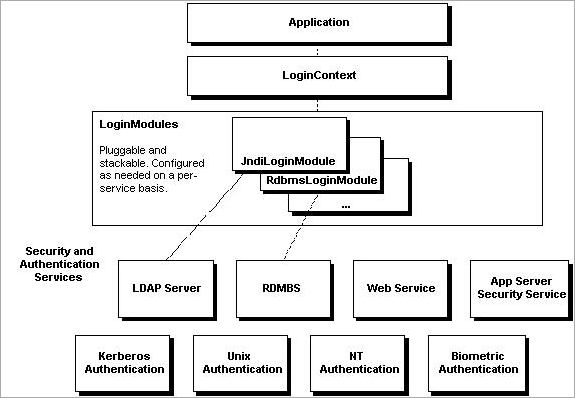
1. 주요 SPI(Service Provider Interface) 인터페이스
1.1 LoginContext 클래스
응용 프로그램과의 인터페이스를 정의 합니다. 응용 프로그램은 Login Context 인터페이스만을 사용하여 로그인 및 로그 아웃을 수행하고 Principal 및 Credential에 대한 정보를 얻을 수 있습니다.
주요 메소드들은 다음과 같습니다.
login() : 로그인을 수행합니다. getSubject() : 로그인으로 인증된 사용자 정보를 리턴 합니다. logout() : 로그아웃을 수행합니다. |
1.2 LoginModule 인터페이스
LoginContext 클래스에서 내부적으로 사용되며 응용 프로그램이 직접 사용하지 않습니다.
서비스 제공자는 이 인터페이스를 구현해야 합니다. 구현된 클래스들은 환경설정 파일을 통하여 LoginContext 생성 시 동적으로 로드 됩니다.
JDK 1.4부터 제공하는 로그인 모듈들은 다음과 같은 것들이 있습니다.
JndiLoginModule : com.sun.security.auth.module.JndiLoginModule Krb5LoginModule : com.sun.security.auth.module.Krb5LoginModule NTLoginModule : com.sun.security.auth.module.NTLoginModule UnixLoginModule : com.sun.security.auth.module.UnixLoginModule |
주요 메소드들은 다음과 같습니다.
initialize() : 모듈 초기화를 수행합니다. login() : 사용자인증(로그인)을 수행합니다. commit() : 모든 로그인 모듈이 성공 한 후에 호출됩니다. abort() : 로그인을 취소합니다. logout() : 로그아웃을 수행합니다. |
1.3 Subject 인터페이스
한 사람에 대한 식별 이름(Principals: login id, 주민번호, email등)들과 인증을 위하여 사용되는 개체 정보(Credentials: 비밀번호, ticket, key)들을 묶어서 관리합니다.
1.4 Principal 인터페이스
개체를 나타내는 id (login id, 주민번호, email, etc)를 나타냅니다.
1.5 Credential 인터페이스
인증을 위하여 사용되는 개체 정보(비밀번호, ticket, key)를 나타냅니다.
1.6 CallbackHandler, Callback 인터페이스
사용자 인증에 필요한 정보 입력(예를 들어 id/pwd)을 처리하는 인터페이스로 응용프로그램에서 직접 구현 하거나 제공되는 다음과 같은 클래스들을 사용할 수 있습니다.
ChoiceCallback : 선택항목들을 나열하고 하나 도는 다수를 선택하도록 합니다. ConfirmationCallback : YES/NO, OK/CANCEL, YES/NO/CANCEL등의 질문에 답하도록 합니다. LanguageCallback : 로케일을 입력 받습니다. NameCallback : 이름을 입력 받습니다. PasswordCallback : 프롬프트를 출력하고 비밀번호를 입력 받습니다. TextInputCallback : 프롬프트를 출력하고 텍스트를 입력 받습니다. TextOutputCallback : 경고 및 에러 메시지를 출력합니다. |
2. JAAS 시스템 구조
3. JAAS 설정파일
3.1 설정파일의 용도
Login Module 구현 클래스들 및 파라미터 그리고 인증 프로세스를 제어하는 플래그들을 설정합니다.
3.2 설정 파일 이름 및 경로
특별한 제한이 없으나 보통 파일명은 “jaas.conf”를 사용합니다. 설정파일 경로는
특별한 제한이 없으며 “javax.security.auth.login.Configuration” 시스템 환경변수를 이용하여 경로를 설정 해야 합니다.
시스템 프로퍼티는 크게 두 가지 방법으로 설정할 수 있습니다. 첫 번째 방법은 운영체제에서 지원하는 시스템 환경 설정 방법을 이용하며 운영 체제 별로 다음과 같이 수행합니다.
- Windows :
set JAVAOPTS=-Djavax.security.auth.login.Configuration=../conf/jaas.conf
또는 GUI로 제공되는 환경 변수 설정 창을 이용합니다.
- Linux :
export JAVAOPTS=-Djavax.security.auth.login.Configuration=../conf/jaas.conf
두 번째 방법은 실행 시 명령 행을 이용하여 설정합니다.
java –Djavax.security.auth.login.Configuration ./jaas.conf AppClass
3.4 설정파일 구조
설정파일은 하나 이상의 Application정의로 구성됩니다. Application은 보통 하나의 응용 프로그램에서 사용 될 LoginModule들의 구현에 대한 정보를 설정합니다. Application내에 LoginModule은 하나 이상 정의할 수 있으며 2-PC(Two-phase commit)로 인증 트랜잭션을 관리합니다.
Application { ModuleClass Flag ModuleOptions; ModuleClass Flag ModuleOptions; ... }; Application { ModuleClass Flag ModuleOptions; ... }; ... |
3.4.1 Application
Application 이름으로 LoginContext 생성시 파라미터에 사용됩니다. 설정 파일에는 여러 응용프로그램들을 위한 LoginModule들이 정의될 수 있으므로 Application 이름으로 구분합니다.
3.4.2 ModuleClass
LoginModule 인터페이스를 구현한 클래스 명을 기록합니다. 하나의 Application에는 하나 이상의 LoginModule들이 기술될 수 있으며 Flag에 따라 LoginModule들을 이용하여 인증을 수행합니다.
3.4.3 Flag
Application에 다수의 LoginModule들이 있을 때 인증(로그인) 과정을 제어하는데 사용됩니다.
- Required: 로그인 모듈 요구됨
인증 성공이 요구되지만 하나이상의 LoginModule이 정의되어 있고 다른 로그인 모둘 중에 하나라도 성공하면 인증이 성공합니다. 따라서 반드시 성공할 필요는 없습니다. 하지만 Application에 LoginModule이 하나만 정의되어 있다면 반드시 성공해야 합니다.
- Requisite: 반드시 성공
LoginModule을 통한 인증이 반드시 성공해야 합니다. 하나 이상의 LoginModule이 정의되어 있고 다른 LoginModule이 모두 성공하여도 이 LoginModule이 실패하면 최종적으로 실패하게 됩니다.
- Sufficient:이 것만 확인되면 충분함.
만약 이 LoginModule의 인증이 성공 하면, 처리할 수 있는 다른 LoginModule이 있다고 하여도 더 이상 인증을 시도하지 않습니다. 즉, 이 인증이 성공하면 바로 인증이 성공하게 됩니다.
- Optional : 선택사항
이 LoginModule은 인증 트랜잭션에 아무런 영향을 주지 않습니다. 즉 LoginModule 인증을 수행하는 것은 옵션입니다.
3.4.4 ModuleOptions
모듈에 전달할 옵션 값을 설정(모듈마다 다름)합니다. 예를 들어 데이터베이스에 연결하여 인증을 수행하는 경우라면 데이터베이스 연결정보가 될 것입니다.
형식 : name=value name=value name=value ………
3.5 설정 파일 예제
Sample { com.sun.security.auth.module.NTLoginModule required debug=true; }; Example { RdbmsLoginModule required debug="true“ driver="org.gjt.mm.mysql.Driver" url="jdbc:mysql://localhost/jaasdb?user=root“; }; |
3.6 JAAS Flow
0) 실행 시 명령 행 인자를 이용하여 시스템 프로퍼티 javax.security.auth.login.config를 설정하고 응용프로그램을 실행합니다.
1) 응용프로그램은 Application Name 및 Subject(사용자 로그인을 위한 정보) 및 Callback(사용자 로그인을 위한 정보를 입력 받기 위한)을 인자로 넘겨LoginContext를 생성합니다.
2) LoginContext는 환경설정 파일에서 Application Name에 해당하는 LoginModule 구현 클래스를 로딩합니다.
3) 생성된 LoginContext의 메소드들을 이용하여 인증 및 권한을 부여합니다.

4. 참고자료
- JAAS 개요 및 LoginModule 작성방법
http://www.javaworld.com/javaworld/jw-09-2002/jw-0913-jaas_p.html
- JavaTM Authentication and Authorization Service (JAAS) Reference Guide
http://java.sun.com/j2se/1.4.2/docs/guide/security/jaas/JAASRefGuide.html
- Introduction to JAAS and Java GSS-API Tutorials
http://java.sun.com/j2se/1.4.2/docs/guide/security/jgss/tutorials/index.html
- javax.security.auth 패키지
자바스터디 네트워크 [www.javastudy.co.kr]
조대협 [bcho_N_O_SPAM@j2eestudy.co.kr]
모든 Java Application은 JVM(Java Virtual Machine)위에서 동작한다.
이 JVM이 동작하는데 있어서, 메모리의 구조와 특히 GC는 Application의 응답시간과 성능에 밀접한 관계를 미친다. 이번 강좌에서는 JVM 의 메모리 구조와 GC 알고리즘 (JDK 1.4.X에 포함된 새로운 알고리즘 포함) 그리고, JVM의 메모리 튜닝을 통한 Application의 성능향상방법에 대해서 알아보도록 하자.
1.GC란 무엇인가?
GC는 Garbage Collection의 약자로 Java 언어의 중요한 특징중의 하나이다.
GC는 Java Application에서 사용하지 않는 메모리를 자동으로 수거하는 기능을 말한다.
예전의 전통적인 언어 C등의 경우 malloc, free등을 이용해서 메모리를 할당하고, 일일이 그 메모리를 수거해줘야했다. 그러나 Java 언어에서는 GC 기술을 사용함에 따라서 개발자로 하여금 메모리 관리에서 부터 좀더 자유롭게 해주었다.
2.GC의 동작 방법은 어떻게 되는가?
1) JVM 메모리 영역
GC의 동작 방법을 이해하기 위해서는 Java의 메모리 구조를 먼저 이해할 필요가 있다.
일반적으로 Application에서 사용되는 객체는 오래 유지 되는 객체보다, 생성되고 얼마안있어서 사용되지 않는 경우가 많다. <그림 1 참조>

<그림 1. 메모리 foot print>
그래서 Java에서는 크게 두가지 영역으로 메모리를 나누는데 Young 영역과 Old 영역이 그것이다.
Young 영역은 생긴지 얼마 안된 객체들을 저장하는 장소이고, Old영역은 생성된지 오래된 객체를 저장하는 장소이다. 각 영역의 성격이 다른 만큼 GC의 방법도 다르다.
먼저 Java의 메모리 구조를 살펴보자.

<그림 2. Java 메모리 구조>
Java의 메모리 영역은 앞에서 이야기한 두 영역 (Young 영역,Old 영역)과 Perm 영역 이렇게 3가지로 영역으로 구성된다.

<표 1. Java 메모리 영역>
2) GC 알고리즘
그러면 이 메모리 영역을 JVM이 어떻게 관리하는지에 대해서 알아보자.
JVM은 New/Young 영역과, Old영역 이 두영역에 대해서만 GC를 수행한다. Perm영역은 앞에서 설명했듯이 Code가 올라가는 부분이기 때문에, GC가 일어날 필요가 없다. Perm영역은 Code가 모두 Load되고 나면 거의 일정한 수치를 유지한다.
○ Minor GC
먼저 New/Young영역의 GC방법을 살펴보자 New/Young 영역의 GC를 Minor GC라고 부르는데, New/Young영역은 Eden과 Survivor라는 두가지 영역으로 또 나뉘어 진다. Eden영역은 Java 객체가 생성되자 마자 저장이 되는곳이다. 이렇게 생성된 객체는 Minor GC가 발생할때 Survivor 영역으로 이동된다.
Survivor 영역은 Survivor 1과 Suvivor2 영역 두 영역으로 나뉘어 지는데, Minor GC가 발생하면 Eden과 Survivor1에 Alive되어 있는 객체를 Suvivor2로 복사한다. 그리고 Alive되어 있지 않는 객체는 자연히 Suvivor1에 남아있게 되고, Survivor1과 Eden영역을 Clear한다. (결과적으로 Alive된 객체만 Survivor2로 이동한것이다.)
다음번 Minor GC가 발생하면 같은 원리로 Eden과 Survivor2영역에서 Alive되어 있는 객체를 Survivor1에 복사한다. 계속 이런 방법을 반복적으로 수행하면서 Minor GC를 수행한다.
이렇게 Minor GC를 수행하다가, Survivor영역에서 오래된 객체는 Old영역으로 옮기게 된다.
이런 방식의 GC 알고리즘을 Copy & Scavenge라고 한다. 이 방법은 매우 속도가 빠르며 작은 크기의 메모리를 Collecting하는데 매우 효과적이다. Minor GC의 경우에는 자주 일어나기 때문에, GC에 소요되는 시간이 짧은 알고리즘이 적합하다.
이 내용을 그림을 보면서 살펴보도록 하자.

<그림 3-1. 1st Minor GC>
Eden에서 Alive된 객체를 Suvivor1으로 이동한다. Eden 영역을 Clear한다.

<그림 3-2. 2nd Minor GC>
Eden영역에 Alive된 객체와 Suvivor1영역에 Alive된 객체를 Survivor 2에 copy한다.
Eden영역과 Suvivor2영역을 clear한다.

<그림 3-3. 3rd Minor GC>
객체가 생성된 시간이 오래지나면 Eden과 Suvivor영역에 있는 오래된 객체들을 Old 영역으로 이동한다.
○ Full GC
Old 영역의 Garbage Collection을 Full GC라고 부르며, Full GC에 사용되는 알고리즘은 Mark & Compact라는 알고리즘을 이용한다. Mark & Compact 알고리즘은 전체 객체들의 reference를 쭉 따라가다면서 reference가 연결되지 않는 객체를 Mark한다. 이 작업이 끝나면 사용되지 않는 객체를 모두 Mark가 되고, 이 mark된 객체를 삭제한다.<그림 4 참고> (실제로는 compact라고 해서, mark된 객체로 생기는 부분을 unmark된 즉 사용하는 객체로 메꾸어 버리는 방법이다.)
Full GC는 매우 속도가 느리며, Full GC가 일어나는 도중에는 순간적으로 Java Application이 멈춰 버리기 때문에, Full GC가 일어나는 정도와 Full GC에 소요되는 시간은 Application의 성능과 안정성에 아주 큰 영향을 준다.

<그림 4. Full GC>
3. GC가 왜 중요한가?
Garbage Collection중에서 Minor GC의 경우 보통 0.5초 이내에 끝나기 때문에 큰문제가 되지 않는다. 그러나 Full GC의 경우 보통 수초가 소요가 되고, Full GC동안에는 Java Application이 멈춰버리기 때문에 문제가 될 수 있다.
예를 들어 게임 서버와 같은 Real Time Server를 구현을 했을때, Full GC가 일어나서 5초동안 시스템이 멈춘다고 생각해보자.
또 일반 WAS에서도 5~10초동안 멈추면, 멈추는동안의 사용자의 Request가 Queue에 저장되었다가 Full GC가 끝난후에 그 요청이 한꺼번에 들어오게 되면 과부하에 의한 여러 장애를 만들 수 있다..
그래서 원할한 서비스를 위해서는 GC를 어떻게 일어나게 하느냐가 시스템의 안정성과 성능에 큰 변수로 작용할 수 있다.
4. 다양한 GC 알고리즘
앞에서 설명한 기본적인 GC방법 (Scavenge 와 Mark and compact)이외에 JVM에서는 좀더 다양한 GC 방법을 제공하고 그 동작방법이나 사용방법도 틀리다. 이번에는 다양한 GC 알고리즘에 대해서 알아보자. 현재 (JDK 1.4)까지 나와 있는 JVM의 GC방법은 크게 아래 4가지를 지원하고 있다.
- Default Collector
- Parallel GC for young generation (from JDK 1.4 )
- Concurrent GC for old generation (from JDK 1.4)
- Incremental GC (Train GC)
1) Default Collector
이 GC 방법은 앞에서 설명한 전통적인 GC방법으로 Minor GC에 Scavenge를, Full GC에 Mark & compact 알고리즘을 사용하는 방법이다. 이 알고리즘에는 이미 앞에서 설명했기 때문에 별도의 설명을 하지는 않는다.
JDK 1.4에서부터 새로 적용되는 GC방법은 Parallel GC와 Concurrent GC 두가지 방법이 있다. Parallel GC는 Minor GC를 좀더 빨리하게 하는 방법이고 (Throughput 위주) Concurrent GC는 Full GC시에 시스템의 멈춤(Pause)현상을 최소화하는 GC방법이다.
2) Parallel GC
JDK1.3까지 GC는 하나의 Thread에서 이루어진다. Java가 Multi Thread환경을 지원함에도 불구하고, 1 CPU에서는 동시에 하나의 Thread만을 수행할 수 밖에 없기때문에, 예전에는 하나의 CPU에서만 GC를 수행했지만, 근래에 들어서 하나의 CPU에서 동시에 여러개의 Thread를 실행할 수 있는 Hyper Threading기술이나, 여러개의 CPU를 동시에 장착한 HW의 보급으로 하나의 HW Box에서 동시에 여러개의 Thread를 수행할 수 있게 되었다.
JDK 1.4부터 지원되는 Parallel GC는 Minor GC를 동시에 여러개의 Thread를 이용해서 GC를 수행하는 방법으로 하나의 Thread를 이용하는것보다 훨씬 빨리 GC를 수행할 수 있다.

<그림 7. Parallel GC 개념도>
<그림 7> 을 보자 왼쪽의 Default GC방법은 GC가 일어날때 Thread들이 작업을 멈추고, GC를 수행하는 thread만 gc를 수행한다. (그림에서 파란영역), Parallel GC에서는 여러 thread들이 gc를 수행이 가능하기 때문에, gc에 소요되는 시간이 낮아진다.
Parallel GC가 언제나 유익한것은 아니다. 앞에서도 말했듯이 1CPU에서는 동시에 여러개의 thread를 실행할 수 없기 때문에 오히혀 Parallel GC가 Default GC에 비해서 느리다. 2 CPU에서도 Multi thread에 대한 지원이나 계산등을 위해서 CPU Power가 사용되기 때문에, 최소한 4CPU의 256M 정도의 메모리를 가지고 있는 HW에서 Parallel GC가 유용하게 사용된다.
Parallel GC는 크게 두가지 종류의 옵션을 가지고 있는데,Low-pause 방식과 Throughput 방식의 GC방식이 있다.
Solaris 기준에서 Low-pause Parallel GC는 ?XX:+UseParNewGC 옵션을 사용한다. 이 모델은 Old 영역을 GC할때 다음에 설명할 Concurrent GC방법과 함께 사용할 수 있다. 이 방법은 GC가 일어날때 빨리 GC하는것이 아니라 GC가 발생할때 Application이 멈춰지는 현상(pause)를 최소화하는데 역점을 뒀다.
Throughput 방식의 Parallel GC는 ?XX:+UseParallelGC (Solaris 기준) 옵션을 이용하며 Old 영역을 GC할때는 Default GC (Mark and compact)방법만을 사용하도록 되어 있다.Minor GC가 발생했을때, 되도록이면 빨리 수행하도록 throughput에 역점을 두었다.
그외에도 ParallelGC를 수행할때 동시에 몇개의 Thread를 이용하여 Minor영역을 Parallel GC할지를 결정할 수 있는데, -XX:ParallelGCThreads=
3) Concurrent GC
앞에서도 설명했듯이, Full GC즉 Old 영역을 GC하는 경우에는 그 시간이 길고 Application이 순간적으로 멈춰버리기 때문에, 시스템 운용에 문제가 된다.
그래서 JDK1.4부터 제공하는 Concurrent GC는 기존의 이런 Full GC의 단점을 보완하기 위해서 Full GC에 의해서 Application이 멈추어 지는 현상을 최소화 하기 위한 GC방법이다.
Full GC에 소요되는 작업을 Application을 멈추고 진행하는것이 아니라, 일부는 Application이 돌아가는 단계에서 수행하고, 최소한의 작업만을 Application이 멈췄을때 수행하는 방법으로 Application이 멈추는 시간을 최소화한다.

<그림 8. Concurrent GC 개념도>
그림 8에서와 같이 Application이 수행중일때(붉은 라인) Full GC를 위한 작업을 수행한다. (Sweep,mark) Application을 멈추고 수행하는 작업은 일부분 (initial-mark, remark 작업)만을 수행하기 때문에, 기존 Default GC의 Mark & Sweep Collector에 비해서 Application이 멈추는 시간이 현저하게 줄어든다.
Solaris JVM에서는 -XX:+UseConcMarkSweepGC Parameter를 이용해 세팅한다.
4) Incremental GC (Train GC)
Incremental GC또는 Train GC라고도 불리는 GC방법은 JDK 1.3에서부터 지원된 GC방법이다. 앞에서 설명한 Concurrent GC와 비슷하게, 의도 자체는 Full GC에 의해서 Application이 멈추는 시간을 줄이고자 하는데 있다.
Incremental GC의 작동방법은 간단하다. Minor GC가 일어날때 마다 Old영역을 조금씩 GC를 해서 Full GC가 발생하는 횟수나 시간을 줄이는 방법이다.

<그림 9. Incremental GC 개념도>
그림 9에서 보듯이. 왼쪽의 Default GC는 FullGC가 일어난후에나 Old 영역이 Clear된다. 그러나, 오른쪽의 Incremental GC를 보면 Minor GC가 일어난후에, Old 영역이 일부 Collect된것을 볼 수 있다.
Incremental GC를 사용하는 방법은 JVM 옵션에 ?Xinc 옵션을 사용하면 된다.
Incremental GC는 많은 자원을 소모하고, Minor GC를 자주일으키고, 그리고 Incremental GC를 사용한다고 Full GC가 없어지거나 그 횟수가 획기적으로 줄어드는 것은 아니다. 오히려 느려지는 경우가 많다. 필히 테스트 후에 사용하도록 하자.
※ Default GC이외의 알고리즘은 Application의 형태나 HW Spec(CPU수, Hyper threading 지원 여부), 그리고 JVM 버전(JDK 1.4.1이냐 1.4.2냐)에 따라서 차이가 매우 크다. 이론상으로는 실제로 성능이 좋아보일 수 있으나, 운영환경에서는 여러 요인으로 인해서 기대했던것만큼의 성능이 안나올 수 있기 때문에, 실환경에서 미리 충분한 테스트를 거쳐서 검증한후에 사용해야 한다.
5. GC 로그는 어떻게 수집과 분석
JVM에서는 GC 상황에 대한 로그를 남기기 위해서 옵션을 제공하고 있다.
Java 옵션에 ?verbosegc 라는 옵션을 주면되고 HP Unix의 경우 ?verbosegc ?Xverbosegc 옵션을 주면 좀더 자세한 GC정보를 얻을 수 있다. GC 정보는 stdout으로 출력이 되기 때문에 “>” redirection등을 이용해서 file에 저장해놓고 분석할 수 있다.
Example ) java ?verbosegc MyApplication
그럼 실제로 나온 GC로그를 어떻게 보는지를 알아보자.

<그림 5. 일반적인 GC 로그, Windows, Solaris>
<그림 5>는 GC로그 결과를 모아논 내용이다. (실제로는 Application의 stdout으로 출력되는 내용과 섞여서 출력된다.)
Minor GC는 ”[GC “로 표기되고, Full GC는 “[Full GC”로 표기된다.
그 다음값은 Heap size before GC인데,GC 전에 Heap 사용량 ( New/Young 영역 + Old 영역 + Perm 영역)의 크기를 나타낸다.
Heap size after GC는 GC가 발생한후에 Heap의 사용량이다. Minor GC가 발생했을때는 Eden과 Survivor 영역으 GC가 됨으로 Heap size after GC는 Old영역의 용량과 유사하다.(Minor GC에서 GC되지 않은 하나의 Survivor영역내의 Object들의 크기도 포함해야한다.)
Total Heap Size는 현재 JVM이 사용하는 Heap Memory양이다. 이 크기는 Java에서 ?ms와 ?mx 옵션으로 조정이 가능한데. 예를 들어 ?ms512m ?mx1024m로 해놓으면 Java Heap은 메모리 사용량에 따라서 512~1024m사이의 크기에서 적절하게 늘었다 줄었다한다. (이 늘어나는 기준과 줄어드는 기준은 (-XX:MaxHeapFreeRatio와 ?XX:MinHeapFreeRation를 이용해서 조정할 수 있으나 JVM vendor에 따라서 차이가 나기때문에 각 vendor별 JVM 메뉴얼을 참고하기 바란다.) Parameter에 대한 이야기는 추후에 좀더 자세히하도록 하자.
그 다음값은 GC에 소요된 시간이다.
<그림 5>의 GC로그를 보면 Minor GC가 일어날때마다 약 20,000K 정도의 Collection이 일어난다. Minor GC는 Eden과 Suvivor영역 하나를 GC하는 것이기 때문에 New/Young 영역을 20,000Kbyte 정도로 생각할 수 있다.
Full GC때를 보면 약44,000Kbyte에서 1,749Kbyte로 GC가 되었음을 볼 수 있다. Old영역에 큰 데이타가 많지 않은 경우이다. Data를 많이 사용하는 Application의 경우 전체 Heap이 512이라고 가정할때, Full GC후에도 480M정도로 유지되는 경우가 있다. 이런 경우에는 실제로 Application에서 Memory를 많이 사용하고 있다고 판단할 수 있기 때문에 전체 Heap Size를 늘려줄 필요가 있다.
이렇게 수집된 GC로그는 다소 보기가 어렵기 때문에, 좀더 쉽게 분석할 수 있게 하기 위해서 GC로그를 awk 스크립트를 이용해서 정제하면 분석이 용이하다.

<표 2. gc.awk 스크립트>
이 스크립트를 작성한후에 Unix의 awk 명령을 이용해서
% awk ?f gc.awk GC로그파일명
을 쳐주면 아래<표 3>와 같이 정리된 형태로 GC 로그만 추출하여 보여준다.

<표 3. gc.awk 스크립트에 의해서 정재된 로그>
Minor와 Major는 각각 Minor GC와 Full GC가 일어날때 소요된 시간을 나타내며, Alive는 GC후에 남아있는 메모리양, 그리고 Freed는 GC에 의해서 collect된 메모리 양이다.
이 로그파일은 excel등을 이용하여 그래프등으로 변환해서 보면 좀더 다각적인 분석이 가능해진다.
※ JDK 1.4에서부터는 ?XX:+PrintGCDetails 옵션이 추가되어서 좀더 자세한 GC정보를 수집할 수 있다.
※ HP JVM의 GC Log 수집
HP JVM은 전체 heap 뿐 아니라 ?Xverbosegc 옵션을 통해서 Perm,Eden,Old등의 모든 영역에 대한 GC정보를 좀더 정확하게 수집할 수 있다.
Example ) java ?verbosegc ?Xverbosegc MyApplication ß (HP JVM Only)
HP JVM의 GC정보는 18개의 필드를 제공하는데 그 내용을 정리해보면 <표 4.>와 같다.
<GC : %1 %2 %3 %4 %5 %6 %7 %8 %9 %10 %11 %12 %13 %14 %15 %16 %17 %18>

<표 4. HP JVM GC 로그 필드별 의미>
이 로그를 직접 보면서 분석하기는 쉽지가 않다. 그래서, HP에서는 좀더 Visual한 환경에서 분석이 가능하도록 HPJtune이라는 툴을 제공한다. 다음 URL에서 다운로드 받을 수 있다.
http://www.hp.com/products1/unix/java/java2/hpjtune/index.html

<그림 6. HP Jtune을 이용해서 GC후 Old영역의 변화 추이를 모니터링하는 화면>
6. GC 관련 Parameter
GC관련 설정값을 보기전에 앞서서 ?X와 ?XX 옵션에 대해서 먼저 언급하자. 이 옵션들은 표준 옵션이 아니라, 벤더별 JVM에서 따로 제공하는 옵션이기 때문에, 예고 없이 변경되거나 없어질 수 있기 때문에, 사용전에 미리 JVM 벤더 홈페이지를 통해서 검증한다음에 사용해야한다.
1) 전체 Heap Size 조정 옵션
전체 Heap size는 ?ms와 ?mx로 Heap 사이즈의 영역을 조정할 수 있다. 예를 들어 ?ms512m ?mx 1024m로 설정하면 JVM은 전체 Heap size를 application의 상황에 따라서 512m~1024m byte 사이에서 사용하게 된다. 그림2의 Total heap size
메모리가 모자를때는 heap을 늘리고, 남을때는 heap을 줄이는 heap growing과 shirinking 작업을 수행하는데, 메모리 변화량이 큰 애플리케이션이 아니라면 이 min heap size와 max heap size는 동일하게 설정하는 것이 좋다. 일반적으로 1GB까지의 Heap을 설정하는데에는 문제가 없으나, 1GB가 넘는 대용량 메모리를 설정하고자 할 경우에는 별도의 JVM 옵션이 필요한 경우가 있기때문에 미리 자료를 참고할 필요가 있다.
※ IBM AIX JVM의 경우
%export LDR_CNTRL=MAXDATA=0x10000000
%java -Xms1500m -Xmx1500m MyApplication
2) Perm size 조정 옵션
Perm Size는 앞에서도 설명했듯이, Java Application 자체(Java class etc..)가 로딩되는 영역이다. J2EE application의 경우에는 application 자체의 크기가 큰 편에 속하기 때문에, Default로 설정된 Perm Size로는 application class가 loading되기에 모자른 경우가 대부분이기 때문에, WAS start초기나, 가동 초기에 Out Of Memory 에러를 유발하는 경우가 많다.
PermSize는 -XX:MaxPermSize=128m 식으로 지정할 수 있다.
일반적으로 WAS에서 PermSize는 64~256m 사이가 적절하다.
3) New 영역과 Old 영역의 조정New 영역은 ?XX:NewRatio=2 에 의해서 조정이 된다.
NewRatio Old/New Size의 값이다. 전체 Heap Size가 768일때, NewRatio=2이면 New영역이 256m, Old 영역이 512m 로 설정이 된다.
JVM 1.4.X에서는 ?XX:NewSize=128m 옵션을 이용해서 직접 New 영역의 크기를 지정하는 것이 가능하다.
4) Survivor 영역 조정 옵션
-XX:SurvivorRatio=64 (eden/survivor 의 비율) :64이면 eden 이 128m일때, survivor영역은 2m가 된다.
5) -server와 ?client 옵션
JVM에는 일반적으로 server와 client 두가지 옵션을 제공한다.
결론만 말하면 server 옵션은 WAS와 같은 Server환경에 최적화된 옵션이고, client옵션은 워드프로세서와 같은 client application에 최적화된 옵션이다. 그냥 언뜻 보기에는 단순한 옵션 하나로보일 수 있지만, 내부에서 돌아가는 hotspot compiler에 대한 최적화 방법과 메모리 구조자체가 아예 틀리다.
○ -server 옵션
server용 application에 최적화된 옵션이다. Server application은 boot up 시간 보다는 user에 대한 response time이 중요하고, 많은 사용자가 동시에 사용하기 때문에 session등의 user data를 다루는게 일반적이다. 그래서 server 옵션으로 제공되는 hotspot compiler는 java application을 최적화 해서 빠른 response time을 내는데 집중되어 있다.
또한 메모리 모델 역시, 서버의 경우에는 특정 사용자가 서버 운영시간동안 계속 서버를 사용하는게 아니기 때문에 (Login하고, 사용한 후에는 Logout되기 때문에..) 사용자에 관련된 객체들이 오래 지속되는 경우가 드물다. 그래서 상대적으로 Old영역이 작고 New 영역이 크게 배정된다. <그림 7. 참조 >
○ -client 옵션
client application은 워드프로세서 처럼 혼자 사용하는 application이다. 그래서 client application은 response time보다는 빨리 기동되는데에 최적화가 되어 있다. 또한대부분의 client application을 구성하는 object는GUI Component와 같이 application이 종료될때까지 남아있는 object의 비중이 높기 때문에 상대적으로 Old 영역의 비율이 높다.

<그림 7. ?server와 ?client 옵션에 따른 JVM Old와 New영역>
이 두옵션은 가장 간단한 옵션이지만, JVM의 최적화에 아주 큰부분을 차지하고 있는 옵션이기 때문에, 반드시 Application의 성격에 맞춰서 적용하기 바란다.
(※ 참고로, SUN JVM은 default가 client, HPJVM는 default가 server로 세팅되어 있다.)
○ GC 방식에 대한 옵션
GC 방식에 대한 옵션은 앞에서도 설명했지만, 일반적인 GC방식이외에, Concurrent GC,Parallel GC,Inceremental GC와 같이 추가적인 GC Algorithm이 존재한다. 옵션과 내용은 앞장에서 설명한 “다양한 GC알고리즘” 을 참고하기 바란다.
7.JVM GC 튜닝
그러면 이제부터 지금까지 설명한 내용을 기반으로 실제로 JVM 튜닝을 어떻게 하는지 알아보도록 하자.
STEP 1. Application의 종류와 튜닝목표값을 결정한다.
JVM 튜닝을 하기위해서 가장 중요한것은 JVM 튜닝의 목표를 설정하는것이다. 메모리를 적게 쓰는것이 목표인지, GC 횟수를 줄이는것이 목표인지, GC에 소요되는시간이 목표인지, Application의 성능(Throughput or response time) 향상인지를 먼저 정의한후에. 그 목표치에 근접하도록 JVM Parameter를 조정하는것이 필요하다.
STEP 2. Heap size와 Perm size를 설정한다.
-ms와 ?mx 옵션을 이용해서 Heap Size를 정한다. 일반적으로 server application인 경우에는 ms와 mx 사이즈를 같게 하는것이 Memory의 growing과 shrinking에 의한 불필요한 로드를 막을 수 있어서 권장할만하다.
ms와mx사이즈를 다르게 하는 경우는 Application의 시간대별 memory 사용량이 급격하게 변화가 있는 Application에 효과적이다.
PermSize는 JVM vendor에 따라 다소 차이가 있으나 일반적으로 16m정도이다. Client application의 경우에는 문제가 없을 수 있지만, J2EE Server Application의 경우 64~128m 사이로 사용이 된다.
Heap Size와 Perm Size는 아래 과정을 통해서 적정 수치를 얻어가야한다.
STEP 3. 테스트 & 로그 분석.
JVM Option에 GC 로그를 수집하기 위한 ?verbosegc 옵션을 적용한다. (HP의 경우 ?Xverbosegc 옵션을 적용한다.)
LoadRunner나 MS Strest(무료로 MS社의 홈페이지에서 다운로드 받을 수 있다.)와 같은 Strest Test툴을 통해서 Application에 Strest를 줘서. 그 log를 수집한다. 튜닝에서 있어서 가장 중요한것은 목표산정이지만, 그만큼이나 중요한것은 실제 Tuning한 Parameter가 Application에 어떤 영향을 주는지를 테스트하는 방법이 매우 중요하다. 그런 의미에서 적절한 Strest Tool의 선정과, Strest Test 시나리오는 정확한 Tuning을 위해서 매우 중요한 요인이다.
○ Perm size 조정
아래 그림8.은 HP JVM에서 ?Xverbosegc 옵션으로 수집한 GC log를 HP Jtune을 통해서 graph로 나타낸 그래프이다. 그림을 보면 Application이 startup되었을때 Perm 영역이 40m에서. 시간이 지난후에도 50m 이하로 유지되는것을 볼 수 있다. 특별하게 동적 classloading등이 수십m byte가 일어나지 않는등의 큰 변화요인이 없을때, 이 application의 적정 Perm 영역은 64m로 판단할 수 있다.

<그림 8. GC 결과중 Perm 영역 그래프>
○ GC Time 수행 시간 분석
다음은 GC에 걸린 시간을 분석해보자. 앞에 강좌 내용에서도 설명햇듯이. GC Tuning에서 중요한 부분중 하나가 GC에 소요되는 시간 특히 Full GC 시간이다.
지금부터 볼 Log는 모社의 물류 시스템의 WAS 시스템 GC Log이다. HP JVM을 사용하며, -server ?ms512m ?mx512m 옵션으로 기동되는 시스템이다.
그림 9를 보면 Peak 시간 (첫번째 동그라미) 14시간동안에 Full GC(동그란점)가 7번일어난것을 볼 수 있다. 각각에 걸린 시간은2.5~6sec 사이이다.
여기서 STEP 1.에서 설정한 AP Tuning의 목표치를 참고해야하는데.
Full GC가 길게 일어나서 Full GC에 수행되는 시간을 줄이고자 한다면 Old 영역을 줄이면 Full GC가 일어나는 횟수는 늘어나고, 반대로 Full GC가 일어나는 시간을 줄어들것이다.
반대로 Full GC가 일어나는 횟수가 많다면, Old 영역을 늘려주면 Full GC가 일어나는 횟수는 상대적으로 줄어들것이고 반대로 Full GC 수행시간이 늘어날 것이다.
특히 Server Application의 경우Full GC가 일어날때는 JVM자체가 멈춰버리기 때문에, 그림 9의 instance는 14시간동안 총 7번 시스템이 멈추고, 그때마다 2.5~6sec가량 시스템이 response를 못하는 상태가 된것이다. 그래서 멈춘 시간이 고객이 납득할만한 시간인지를 판단해야 하고, 거기에 적절한 Tuning을 해야한다.
Server Application에서 Full GC를 적게일어나게하고, Full GC 시간을 양쪽다 줄이기 위해서는 Old영역을 적게한후에, 여러개의 Instance를 동시에 뛰어서 Load Balancing을 해주면, Load가 분산되기 때문에 Full GC가 일어나는 횟수가 줄어들테고, Old 영역을 줄였기 때문에, Full GC에 드는 시간도 줄어들것이다. 또한 각각의 FullGC가 일어나는동안 하나의 서버 instance가 멈춰져 있어도, Load Balancing이 되는 다른 서버가 response를 하고 있기때문에, Full GC로 인한 Application이 멈추는것에 의한 영향을 최소화할 수 있다.

<그림 9. GC 소요시간>
데이타에 따라서 GC Tuning을 진행한후에는 다시 Strest Test를 진행해서 응답시간과 TPS(Throughput Per Second)를 체크해서 어떤 변화를 주었는지를 반드시 체크해봐야한다.

<그림 10. GC후의 Old 영역>
그림 10은 GC후에 Old 영역의 메모리 변화량을 나타낸다.
금요일 업무시간에 메모리 사용량이 올라가다가. 주말에가서 완만한 곡선을 그리는것을 볼 수 있다. 월요일 근무시간에 메모리 사용량이 매우 많고, 화요일에도 어느정도 메모리 사용량이 있는것을 볼 수 있다. 월요일에 메모리 사용량이 많은것을 볼때, 이 시스템의 사용자들이 월요일에 시스템 사용량이 많을 수 있다고 생각할 수 있고, 또는 다른 주의 로그를 분석해봤을때 이 주만 월요일 사용량이 많았다면, 특별한 요인이나 Application 변경등이 있었는지를 고려해봐야할것이다.
이 그래프만을 봤을때 Full GC가 일어난후에도 월요일 근무시간을 보면 Old 영역이 180M를 유지하고 있는것을 볼 수 있다. 이 시스템의 Full GC후의 Old영역은 80M~180M를 유지하는것을 볼 수 있다. 그래서 이 시스템은 최소 180M이상의 Old 영역을 필요로하는것으로 판단할 수 있다.
STEP 4. Parameter 변경.
STEP 3에서 구한 각 영역의 허용 범위를 기준으로 Old영역과 New 영역을 적절하게 조절한다.
PermSize와 New영역의 배분 (Eden,Survivor)영역등을 조정한다.
PermSize는 대부분 Log에서 명확하게 나타나기 때문에, 크게 조정이 필요가 없고 New영역내의 Eden과 Survivor는 거의 조정하지 않는다. 가장 중요한것은 Old영역과 New 영역의 비율을 어떻게 조정하는가가 관건이다.
이 비율을 결정하면서, STEP1에서 세운 튜닝 목표에 따라서 JVM의 GC Algorithm을 적용한다. GC Algorithm을 결정하는 기본적인 판단 내용은 아래와 같다.

이렇게 Parameter를 변경하면서 테스트를 진행하고, 다시 변경하고 테스트를 진행하는 과정을 거쳐서 최적의 Parameter와 GC Algorithm을 찾아내는것이 JVM의 메모리 튜닝의 이상적인 절차이다.
지금까지 JVM의 메모리 구조와 GC 모델 그리고 GC 튜닝에 대해서 알아보았다.
정리하자면 GC 튜닝은 Application의 구조나 성격 그리고, 사용자의 이용 Pattern에 따라서 크게 좌우 되기때문에, 얼마만큼의 Parameter를 많이 아느냐 보다는 얼마만큼의 테스트와 로그를 통해서 목표 값에 접근하느냐가 가장 중요하다.
 |
| <그림 1> 숫자로 보는 자바 |
| 자바SE(Java Standard Edition)? |
자바 플랫폼 스탠다드 에디션에는 두 가지 주요 제품이 있다. Java SE Runtime Environment(이하 JRE)와 Java SE Development Kit(이하 JDK)가 그것이다. JRE는 자바 API, 자바 버츄얼 머신, 그리고 자바 프로그래밍 언어상에서 구동되는 애플릿과 애플리케이션에 필요한 컴포넌트이다. 자바SE는 또한 엔터프라이즈 소프트웨어 개발 및 디플로이를 위한 자바엔터프라이즈 에디션(Java EE)의 근간이기도 하다. JDK는 JRE상에 있는 모든 구성요소 외에도 애플릿과 애플리케이션을 개발하는 데에 필요한 컴파일러와 디버거 등의 툴도 포함한다.
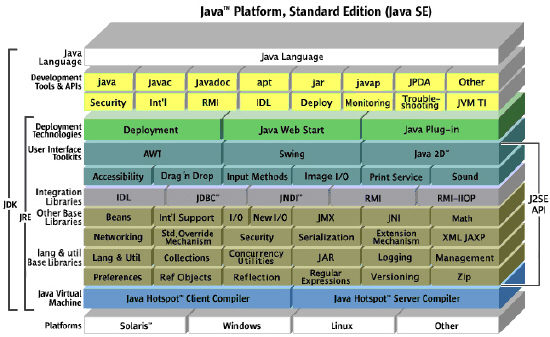 |
| <그림2> 자바 플랫폼 스탠다드 에디션 (Java SE) |
<그림 2>는 이러한 자바SE의 플랫폼상의 모든 컴포넌트 기술을 보여준다.
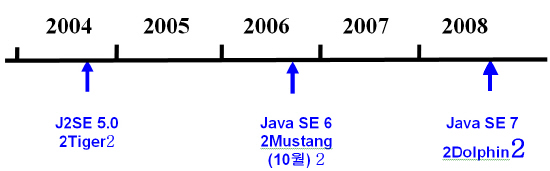 |
| <그림 3> 자바SE의 로드맵 |
<그림 3>에서도 알 수 있듯이 자바플랫폼 스탠다드 에디션은 새로운 특장점이 소개될 때마다 약 18개월의 주기로 업데이트 된다. 그 외에도 매 8주에서 16주를 주기로 버그 수정이 업데이트 된다.
썬은 지난 2005년 자바원에서 J2SE의 이름을 자바SE로 변경했다. 이후 5.1과 6.1이라는 추가 버전 없이 오는 2006년 10월 발표 예정인 자바SE 6 이후에는 버그 수정에서부터 특장점까지 커뮤니티 상에서의 기여 및 참여를 통해 업데이트 되며, 자바SE 7(코드명: 돌핀)은 2008년 하반기에 발표할 예정이다.
자바SE 6(코드명: 머스탱)는 지난 2004년 발표한 자바SE 5.0(코드명: 타이거)의 버그를 수정하고, 기존 프로그램을 운영할 수 있도록 했다. 또 질적 향상을 위해 소스와 바이너리를 활용하여 개발자들이 보다 오픈된 환경에서 개발할 수 있도록 개선되었다. 자바SE 6는 호환성, 안정성, 질적 향상에 중점을 두어 개발되었다.
 |
| <표 1> JDK |
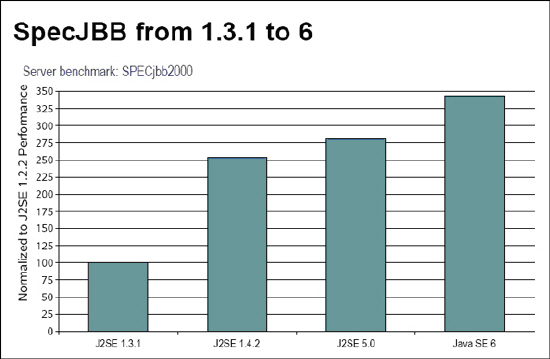 |
| <표 2> 서버 벤치 마크:SPECjbb2000(기존 버전과 비교시 서버 벤치마크상 성능향상을 보여준다.) |
자바SE 6는 지속적으로 자바 성능 향상에 중점을 두고, 클라이언트, 서버 양쪽의 성능 향상, 코어 JVM (Java Virtual Machine, 자바 버츄얼 머신)으로의 업그레이드, GC 스케일링과 패럴리즘, 라이브러리 튜닝, 자바2D그래픽 렌더링으로의 업그레이드와 구동 속도를 높이는 등의 기능이 강화되었다(<표 1>과 <표 2> 참조). 그 외에도 모니터링과 관리기능을 중점으로 보다 나은 JVM레벨의 테스팅, 메모리 핸들링 향상, JMX업그레이드,솔라리스 Dtrac와의 연계 기능 향상과 J콘솔 업그레이드 등 모니터링 기능이 한층 강화되었다. (<화면 1> 참조)
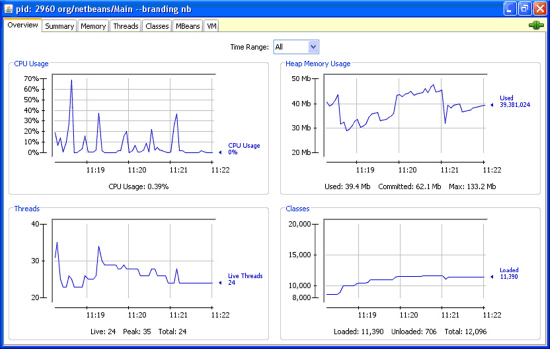 |
| <화면 1> J컨솔 업그레이드 |
이렇듯 자바SE 6는 고객들의 자바SE 의존도가 높은 만큼 호환성, 안정성, 질적 향상을 중점으로 최신 기술과 개발자들의 니즈를 반영하여 다양한 특장점이 업데이트 되고 있다. J2SE 1.4 버전이후에 자바 스탠다드 에디션의 중심에 있는 XML은 주요 데이터 교환 기술로 웹서비스의 근간이 되고 있다. 자바SE 6는 클라이언트 중심뿐만 아니라 경량의 서버에까지 적용되는 클라이언트 스택으로(JSR 105, 173,181, 222,224) 업데이트된 코어XML 스택을 포함한다.
또한, 개발 용이성을 주제로 개발자들이 보다 생산적으로 작업을 단순화할 수 있도록 스크립트 언어 지원 (JSR-223), XML데이터 지원을 포함한 JDBC 4.0 (JSR-221), 기타 API 등이 향상
되었다. 이외에도 데스크톱 자바는 모든 자바 성공에 있어 중요한 만큼 Java SE 6 또한 이러한 기능 향상을 포함하고 있다. 아발론 룩앤필을 포함한 윈도우 비스타 지원과 그동안의 자바 기술의 단점으로 지적되어 온 GUI를 개선하기 위해 윈도우 시스템의 트레이 기능 지원, 스플래시 스크린 지원, 그래픽 파이프라인 부스트 등 많은 GUI기능을 업그레이드했다.
자바SE 6는‘보다 공개된 (Open)개발 환경’(소스와 바이너리면에서)을 목적으로 많은 개발자들의 참여와 기여를 기다리고 있다. 이 같은 자바SE 6 (머스탱)의 성공적인 런칭과 구현을 위해서는 개발자들의 적극적인 커뮤니티 참여가 절실히 필요하다.
이러한 공동 참여와 기여를 통해 현 개발환경에서 필요한 개발자들의 니즈를 반영하여 새로운 특장점을 업데이트하고 버그를 수정하여 자바SE 6가 완성된다. 이러한 시도는 기존의 베타 버전과는 다른 새로운 경험 및 발상의 전환이 될 것이다. 참여 URL은‘mustang.dev.java.net’이다.
| 자바SE 6의 장점 |
자바SE 로드맵 상에서 볼 수 있는 자바SE 7(코드명: 돌핀)은 기존 자바SE 6(머스탱) 버전보다 더 개방된 환경에서 다이나믹한 언어를 지원할 뿐 아니라 확대된 XML 지원 기능과 보다 확대된 XML지원 등을 포함할 예정이다. 자바SE 7의 새로운 주요 특장점들은 10월 Java SE 6 출시이후에 보다 자세한 내용이 공개될 예정이다.
 |
| <그림 4>Mustang Features |
| 야생마 자바SE6 길들이기 |
이번에는 자바SE 6의 새로운 기능 중의 하나인 트레이(Tray) API를 이용한 예제를 살펴보자. 여기에서 트레이란 윈도우 GUI에서 태스크바(Taskbar) 오른쪽에 자리 잡는 작은 기능성 아이콘들이 들어가는 자리를 말한다. 보통 늘 떠 있어야 하는 애플리케이션들이 화면에 작게나마 현재 상태를 나타내고자 할 때 쓰인다. 예를 들어 메신저 창을 닫아도 메신저의 상태와 새 메시지 도착 등을 알리는 창구가 된다.
트레이에 아이콘을 두는 것은 윈도우 애플리케이션에 있어 사용자의 주목을 쉽게 끌 수 있고, 태스크바를 감추지 않는 이상 늘 떠 있어 자주 쓰는 기능의 호출에 대한 접근성을 향상시키는 장점이 있다. 따라서 자바 애플리케이션도 이런 트레이 아이콘을 가질 수 있다면 더욱 풍부한 사용자 경험을 제공할 수 있음은 두말할 나위도 없다. 원래 트레이 API는 JDIC(JDesktopI ntegration Components)라는 프로젝트의 일환으로, J2SE 1.4.2 이상이면 쓸 수 있는 부가 라이브러리로 시작했지만, 자바SE 6에는 기본 탑재되었다. 따라서 다음과 같이 패키지 이름만 다를 뿐 API 자체는 동일하므로 이제 소개할 예제를 간단히 포팅 할 수 있다.
JDIC Mustang
org.jdesktop.jdic.tray.SystemTray => java.awt.SystemTray
org.jdesktop.jdic.tray.TrayIcon => java.awt.TrayIcon
<리스트 1>은 본래 제우스 5를 부트.다운할 때 사용하려고 만든 것을 제우스 6 용으로 재구성한 것이다. 이 달의 디스켓 파일을 다운로드 받아서 압축을 푼 뒤에 핵심이 되는 코드를 살펴보자.
| ||||
| ||||
 |

우선 이렇게 짧은 코드로 트레이를 사용하는 애플리케이션을 만들 수 있다는 점이 놀랍다. 자바가 플랫폼에 독립적이기 때문이 트레이가 지원되는 OS(현재는 윈도우와 유닉스 일부)인지를 확인한 다음, 보통의 스윙(Swing) 애플리케이션처럼 아이콘용 이미지를 읽어 들이고 동작에 필요한 액션 리스너를 만다. 마지막으로 시스템 트레이에 트레이 아이콘을 추가하면 끝난다(아이콘 이미지는 예제 프로젝트 파일에 포함되어 있다). 이 애플리케이션을 실행시키는데 필요한 스크립트인 jeus-tray.bat은 다음과 같다.
%MUSTANG_HOME%\bin\java -cp bin ias.tray.JeusTray%JEUS_HOME% %*
이 배치 파일을 실행하려면 MUSTANG_HOME 환경 변수를 자바SE 6 설치 디렉토리로 잡아 줘야 한다. 예를 들어 다음과 같이 하면 된다.
set MUSTANG_HOME=c:\java\sdk\jdk6
JEUS_HOME은 제우스를 설치하면 자동으로 잡히므로 추가적으로 설정할 필요는 없다. jeus-tray.bat를 실행할 때에는 세 개의 인수를 넘겨주어야 한다.
jeus-tray xias jeus jeus
첫 번째 인수는 제우스가 설치된 노드 이름(보통은 컴퓨터 이름이다), 나머지 인수는 제우스 관리를 위한 어드민의 사용자 이름과 암호이다. 이렇게 제우스 제어를 위한 정보를 알려줘야 부트.다운이 가능하다. 실행시키면 다음과 같은 아이콘이 트레이에 표시된다.
 |
| <화면 2> 제우스 트레이가 뜬 상태 |
에서 마우스 오른쪽 버턴을 누르면 아래와 같은 메뉴가 나온다.
 |
| <화면 3> 제우스 트레이 명령 선택 |
 |
| <화면 4> 제우스가 부팅된 상태를 가리키는트레이 아이콘 |
앞서는 빨간색으로 X가 되던 부분이 부트가 되고 나면 녹색 진행 표시로 바뀐다. 물론 down을 선택하면 다시 X가 표시된다.
down 기능을 쓰기 위해서는 예제 프로젝트 파일에 동봉된 jeusdown. bat를 JEUS_HOME/bin에 넣어두어야 한다.
아주 간단한 예제지만, 그 활용처는 무궁무진하고 리눅스와 솔라리스에서도 쓸 수 있어 윈도뿐만 아니라 다양한 GUI 환경에서 트레이의 편리함을 누릴 수 있다는 점이 매력적이다. 앞으로 자바 메신저나 RSS 리더에서 멋지게 사용되기를 기대해본다.
| 자바 브랜드 강화 및 미래 |
2005년으로 탄생 10주년을 맞은 자바는 이를 기념하기 위해 자바 브랜드를 새롭게 단장했다. 더욱 쉽고 심플한 디자인의 자바브랜드는‘한번 쓰면 어디에든 적용된다’는 주제 하에 전 세계적으로 PC와 휴대폰을 포함해 약 80%이상의 무선 애플리케이션 상에 적용되고 있다는 점이 많은 제조사와 컨슈머 고객사들이 자바 브랜드를 선호하는 이유다.
8세부터 80세까지, 200여개의 언어의 모든 사람들이 사용하는 자바 브랜드(로고)는 이러한 자바의 역사를 대변하고 있다. 보다 단순화된 자바 로고와 이름은 약 180여개의 자바 라이센서들의 샘플 집단에서 인터뷰를 거쳐 완성되었다.
| ||||||||
| ||||||||
|

이렇듯 자바는 브랜드에서부터 기술의 발전에 이르기까지 개발자들의 참여와 기여를 통해 하나의 생태계로서 발전하고 있다.
 |
| <그림5> 자바 플랫폼의 성장과 미래 |
마지막으로 현재 개발환경이 스탠다드 에디션이든 엔터프라이즈 에디션이든 더욱더 단순하면서도 풍부한 자바 기술의 향상을 위해서는 자바 개발자라는 공동체내에서 개발자들의 커뮤니티 참여가 무엇보다도 중요하다(<그림 5> 내용 참조). @
* 이 기사는 ZDNet Korea의 제휴매체인 마이크로소프트웨어에 게재된 내용입니다.
JDK 5.0 에서의 새로운 변화
JDK 5.0에서는 프로그래밍의 유연함을 좀더 향상시키기 위해서 여러 가지 기능들이 개선되고 추가되었다. 이번 절에서는 JDK 5.0 에 오면서 변화된 여러 기능을 알아보자. 그렇지만 자바를 처음접하는 이들에게는 전혀 이해가 안 되는 얘기들일 것이다. 따라서 모든 내용을 이해할 생각을 하지 말고 그냥 "이런 것이 있구나!"하고 참고적으로 알아두길 바란다. 그렇다고 그냥 넘어가지 말자. 이전 버전과 비교해서 달라진 부분을 알고 있다면 향후 프로그래밍을 할 때 크게 도움을 받을 수 있기 때문이다.
less..
예전부터 자바 커뮤니티의 기대를 받아왔던 제네릭 타입(Generic Type)이 드디어 JDK 5.0 버전의 일부로 포함되었다. 제네릭 타입이 적용된 것을 Collection API에서 가장 먼저 찾아볼 수 있다. Collection API 는 Linked List, ArrayList, 그리고 HashMap과 같이 하나 이상의 클래스가 공통으로 사용할 수 있는 기능들을 제공한다.
JDK 5.0 버전 이전의 Collection API 에서는 COllection 객체를 Onject 클래스에 저장하기 때문에 컴파일 타임에 발생하는 타입 오류(Type Mismatch)을 확인할 수 없다. 이러한 문제는 런타임할 때 ClassCastException이 발생하는 형태로 확인해야 하므로 Collection에 대입된 자료의 확인 여부를 어쩔 수 없이 런타임할 때까지 유도해야만 확인할 수 있었다.
하지만 JDK 5.0에서는 이러한 번거로움을 탈피하기 위해서 일반화된 API를 사용하려면 컴파일 할 때 단지 <> 사이에 사용할 자료 타입을 선언해주기만 하면 캐스팅은 더 이상 할 필요가 없다. 나아가서 사용된 Collection에 삽입되는 객체의 자료타입이 잘못 대입될 경우, 이젠 런타임 때가 아닌 컴파일 때에 확인할 수 있다. 예를 들어, 옷을 직접 입지 않고 옷의 사이즈를 확인하는 것만으로 내게 맞는 옷인지 확인할 수 있게 된 것이다.
2. 메타데이터
JDK 5.0에 포함된 ‘메타데이터(Metadata)' 기능을 통해 자바 클래스, 인터페이스, 메서드, 그리고 필드(변수나 상수) 등에 추가적인 정보들을 부과할 수 있게 되었다. 이 추가적인 정보는 javac 컴파일러 외에도 여러 툴로부터 읽어 들일 수 있으며 설정하기에 따라 클래스 파일에 저장할 수도 있고 Java Reflection API를 통해 런타임할 때에 접근할 수도 있다.
아무래도 메타데이터가 JDK 5.0에 추가된 주된 이유는 여러 개발 툴과 런타임 툴간의 공통된 인프라를 구축함으로써 프로그래밍과 개발에 소요되는 수고를 덜고자 하기 위함이라 볼 수 있다.
3. 개선된 루프
Collection API의 iterator는 상당히 자주 사용되는 객체다. 이는 Collection 내에서 이동하는 기능을 제공하는데, 개발을 하다보면 이런 Collection 들과 배열들을 반복적으로 사용할 때가 많다. 하지만 iterator와 인덱스 변수들로 인해 복잡함과 다소 불편함을 느낄 때가 많다. ‘개선된 루프(Enhanced for Loop)'는 그런 불편함에서 나올 수 있는 오류 발생 가능성을 줄여준다. 컴파일러는 필요한 루프 코드를 생성하게 되고, Generic Type을 함께 사용하게 되면 더 이상 일일이 자동 형 변환(casting)을 해주지 않아도 되므로 프로그래밍을 하는 데 더욱 더 편해진다.
예를 들어, 기차를 탈 때와 비슷하다. 기차를 이루는 각각의 호차들마다 번호표가 있게 마련인데, 호차마다 이 번호표가 없다고 가정해보자. 그렇다면 모든 승객들이 맨 앞의 기차부터 일일이 숫자로 세어 자신이 배정받은 호차에 타게 되는 불편함이 있게 된다. 그리고 숫자로 호차들을 세다가 중간에서 잘못 세게 되면 다른 사람 자리로 모든 호차들을 미리 나열화하고 그 호차들에게 번호표를 미리 붙여놓음으로써 불편함을 줄여놓은 것이다. JDK 5.0에서 얘기하는 ‘개선된 루프’가 바로 이와 비슷한 반복적 비교문을 강화한 것이다.
[이전버전]
for(int i=0 ; i<10 ; i++)
System.out.println(ar[i]);
[JDK 5.0]
for(string n : ar)
System.out.println(n);
위 예문과 같이 [이전버전]에서는 int형 변수 i와 같은 index값을 사용하여 배열의 요소들을 참조하는 데 사용한다. 하지만 배열의 길이가 만약 9개라면 6장에서 배우게 되는 예외 중 하나인 ArrayIndexOutBoundsException이 발생하게 된다. 하지만 [JDK 5.0]에서 제공되는 개선된 루프를 사용하게 되면 내부적으로 나열화 작업이 자동적으로 이루어지므로 [이전버전]의 예문과 같이 예외에 대한 우려는 하지 않아도 된다.
4. 오토박싱 / 언박싱
int 또는 bollean 과 같은 기본 자료형(primitive Type)과 이에 상응하는, 즉 Integer 또는 Boolean과 같은 Wrapper 클래스 타입간의 자료 변환 작업이 EO로는 불필요할 정도의 많은 코딩을 요구하는 경우 있다. 특히 Collection API 중 메서드의 인자로서 사용하기 위한 경우라면 더더욱 골치 아픈 일이 될 수 있었는데, JDK 5.0 에서는 int와 Integer같의 변환 작업을 컴파일러가 맡아서 처리하므로 불필요함을 크게 줄이게 되었다.
간단하게 예를 들자면 어느 날 집으로 새로운 컴퓨터가 배달되었다. 기분이야 두말하면 잔소리지만 포장을 뜯는 것이 여간 신격 쓰이는 것이 아니다. 물론, “기분이 날아갈 듯한데 그게 무슨 대수냐?”라는 생각이 들지도 모른다. 하지만 고객이 원한다면 이런 “포장까지 깔끔하게 서비스 해주는 택배회사가 있다면...”이라는 생각을 한 번쯤은 해봤다(아마 대박이 날지도 모를 일이다.) JDK 5.0 에서는 이런 귀찮은 변환 작업을 자동적으로 제공하는데, 이를 ‘오토박싱/언박싱(Autoboxing/Unboxing)'이라 하는 것이다.
이전 버전에서는 Ingeter 클래스의 내부값을 int로 가져오려면 그러한 일을 해주는 특정 메서드를 호출해야만 하는데, JDK 5.0으러 오면서 그런 수고를 덜었다.
[이전버전]
Integer iTest = new Integer(500);
int i = iTest.intValue();
[JDK 5.0]
Integer iTest = new Integer(500);
int i = iTest;
간단히 정리하면, 위 예문의 핵심은 마치 객체가 기본 자료형에 대입되는 것처럼 보이지만 이때 변환작업을 컴파일러가 알아서 해준다는 것이다.
5. static import
static import 기능은 ‘import static'의 형태로 사용되는데, 이를 통해 클래스로부터 상속받지 않고 또는 해당 클래스를 일일이 명시하지 않고도 static 상수들에 접근할 수 있다. 다시 말해 기존과 같이 BorderLayout.CENTER라고 사용할 필요 없이 JDK 5.0에서 ’import static'을 적용한 이제부터는 단순히 CENTER라고만 해도 사용할 수 있다는 것이다.
[이전버전]
JPanel p1 = new JPanel(new FlowLayout(FlowLayout.RIGHT));
[JDK 5.0]
import static java.awt.FlowLayout.*;
...
JPanel p1 = new JPanel(new FlowLayout(RIGHT));
위의 [이전버전]과 [JDK 5.0]의 예문이 너무 간단하여 [JDK 5.0]에서 크게 유익한 점을 못 느낄 수도 있다. 하지만 실제 예제를 다루게 되면 그렇지가 않다. 하지만 실제 예제를 다루게 되면 그렇지가 않다. 또는 System.out.println("..."); 이라는 문장이 많이 사용될 경우 out까지를 static import로 미리 적용해두면 코드의 내용이 상당히 편리해질 것이다.
6. Formatter과 Scanner
이제 JDK 5.0 버전에서는 Formatter 클래스가 제공되는데, 이를 C style format imput / output 이라 하여 C 언어에서 사용되었던 printf 형태의 기능이 추가되어 정형화된 출력을 할 수 있게 되었다. 더 나아가 이로써 같은 텍스트 형태를 유지하면서 큰 수정 작업 없이 C 언어의 응용프로그램으로부터 소스를 물려받아 자바로의 변환(migration)도 쉽게 할 수 있다. 다음은 예문이다.
System.out.printf("%s %5d%n", "총점:“, 500);
이 예문처럼 %로 시작하는 포맷 형식을 설정하고 그 형식에 맞도록 정형화된 출력을 목적으로 하는 것이 Formatter다.
Scanner 클래스는 기존에 사용되었던 Stream들에 없었던 파싱(parsing) 기능을 부여하여 효율적으로 자료를 유입하기 위한 클래스다. 기존의 Stream들은 Character 기반의 Stream인 BufferedReader를 쓴다하더라도 한 번에 한 줄씩 읽어 들이는 수 밖에 없었다. 하지만 Scanner 클래스를 사용하면 한 번에 전체를 읽어 들일 수도 있으며, 때에 따라서는 한 줄 단위로 읽을 수도 있다. 이러한 것들은 Pattern 클래스 또는 문자열로 되어 dLT는 구분자의 패턴을 useDelimiter()라는 메서드로 간단하게 변경하여 유연성을 높이고 있다.
7. Varargs(Variable Arguments)
JDK 5.0 이전의 버전에서는 특정 메서드를 정의할 때 인자(argument)의 타빙과 수를 정해두고 호출할 때 전달되는 인자의 수가 일치하지 않을 경우에는 메서드를 호출할 수 없었다. 이런 문제로 인해 많은 개발자들이 오버로딩법 또는 메서드에 배열객체로 인자를 지정하고 배열 객체를 사용하여 이 문제를 해결했지만 매번 호출할 때의 배열화 작업이 너무 불편했던 것이 사실이다.
이제 varargs 기능을 사용하여 여러 개의 인자를 매개변수(parameter)의 형태로 전달할 수 있다. 인자로 받는 메서드에서 ‘...’이라고 명시를 해주면 이를 통해 메서드를 수행하는데 필요한 인자의 수를 유연하게 구현할 수 있다.
[이전버전]
class VaraTest {
public static void test(Object args){
System.out.println(args);
}
public static void main(String args[]){
test("Java5");
test("Java5", " Varargs", " Test!"); // 인자 전달에 대한 오류!
}
}
[JDK 5.0]
class HelloWorld {
public static void test(Object ... args){
for(int i = 0 ; i < args.length ; i++) {
System.out.print(args[i]+",");
}
System.out.println();
}
public static void main(String args[]){
test("Java5");
test("Java5", " Varargs", " Test!");
test(new Integer(1000), new Float(3.14));
}
}
[출력결과]
Java5,
Java5, Varargs, Test!,
1000,3.14,
이전 버전에서는 인자의 수만 달라도 컴파일 오류가 발생했다. 하지만 JDK 5.0 에서는위처럼 Varargs 법을 사용하게 되면 보는 것과 같이 인자가 한 개이든, 세 개이든 인자의 수를 유연하게 받아주는 특징이 있어 작업의 효율을 높일 수 있다.
8. Simpler RMI interface generation 기법
원격 인터페이스에 대한 stub를 생성하는 데 있어서 더 이상 rmi 컴파일러인 rmic를 사용할 필요가 없으므로 RMI 기법을 더욱 더 간편하게 사용할 수 있게 되었다. Dynamic Proxy가 소개됨에 따라 stub가 제공하는 정보는 이제 런타임할 때 찾을 수 있게 되었기 때문이다.
이외에도 JVM 관련 기능들과 프로토콜을 감시하는 모니터링 기능 그리고 JDBC RowSets 등 여러 기능이 추가되고 개선되었다. 하지만 이 책의 수준에 맞춰 이 정도의 소개로 마무리하며 JDBC Rowstes 과 같이 꼭 알아야 하는 것들은 해당되는 장에서 소개한다.
+--+
| | 출생월 (MM = 01 - 12 사이의 값)
| | +--+
| | | | 출생일 (DD = 01 - 31 사이의 값)
| | | | +--+
| | | | | | 남,여 구분 (1, 3 = 남자, 2, 4 = 여자 )
| | | | | | |
Y Y M M D D - X C
+------------------------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 10 11 12 | index
| 6 6 0 5 1 0 - 1 3 2 1 6 1 1 | data
| 2 3 4 5 6 7 8 9 2 3 4 5 KEY | mask
+------------------------------------------------------------------+
(11- {12+ 18+ 0+ 25+ 6+ 0+ 8+ 27+ 4+ 3+ 24+ 5}%11)% 10 == 1
* 주민등록 번호 검사 비트 검사 방법
1) 주민등록 번호에 앞에서부터 2,3,4,5,6,7,8,9,2,3,4,5를 차례로 곱한다. {0..11}%8+2
2) 각각의 값을 모두 더한다. sum
3) 이 합을 11로 나눈다. 그러면 나머지는 0,1,2,3,4,5,6,7,8,9,10 중의 하나이다.
4) 11에서 나머지를 뺀다.
5) 이때 나머지 값이 10을 넘으면 10를 빼고, (11-sum%11)%10
그렇지 않으면 나머지 값이 주민등록 검사 비트이다.
예) 660510-1321611
6 * 2 + 6 * 3 + 0 * 4 + 5 * 5 + 1 * 6 + 0 * 7 + 1 * 8 + 3 * 9 + 2 * 2 + 1 * 3 + 6 * 4 + 1 * 5 = 132 : 합계
132 % 11 = 0 : 나머지값
(11 - 0) % 10 = 1 : 결과값
따라서 키 플래그는 1이다. 그리고 마지막 자리의 체크플래그는 1이다.
키플래그 == 체크플래그
 XmlUtil.java
XmlUtil.java Prev
Prev
