'MySQL'에 해당되는 글 6건
- 2009.03.02 Windows에서 MySQL 설치하기
- 2009.03.02 MySQL Cluster
- 2009.03.02 MySQL리플리케이션
- 2009.02.25 [번역]MySQL Table Joins
- 2009.02.25 MySQL - Explain 정보보는법
- 2009.02.25 MySQL 쓰면서 하지 말아야 할 것 17가지
Windows에서 MySQL 설치하기
Windows에서 MySQL 설치하기
|
Windows에서는 MSI(Microsoft Windows Installer)를 사용한다. Windows 2000 / XP / 2003 Server에서 사용할 수 있으며, http://dev.mysql.com/downloads/mysql/5.0.html에서 다운로드받을 수 있다("Windows Downloads"로 검색하라). 필수 설치 파일을 받았다면 더블클릭하여 실행한다.
다음 설명은 Windows용 MySQL 5.0.22 기준이다. 설치 과정은 Windows 환경에는 독립적이다.
[노트]
MSI 형식 이외의 설치 방법도 제공한다. "Complete Package" 방식과 "Noinstall Archive" 방식이 그것이다. "Essentials Package" 이외의 방법을 사용한다면 MySQL 매뉴얼을 반드시 읽어보아야 한다. 매뉴얼은 http://dev.mysql.com/doc/refman/5.0/en/windows-choosing-package.html에서 구할 수 있다.
본격적으로 설치를 시작해보자(MySQL AB 웹 사이트에서 MSI 파일을 다운로드했다고 가정한다).
1. MSI 파일을 더블클릭한다. [그림 2-4]와 같은 화면이 나오면 [Next] 버튼을 누른다.
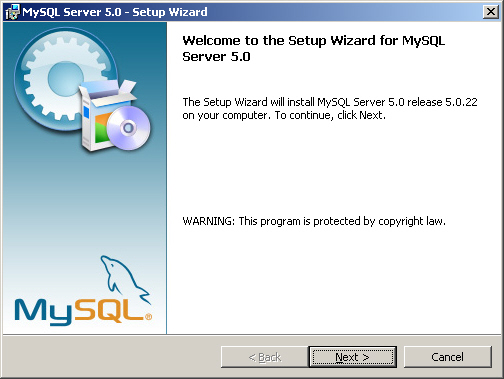
[그림 2-4] Windows용 설치 마법사 시작 화면
2. "Typical", "Complete" 또는 "Custom" 중에 하나를 선택한다([그림 2-5] 참조). "Custom"은 MySQL의 구성 요소들을 선택적으로 설치할 수 있다. "Complete"는 MySQL의 모든 요소를 설치한다. 즉, 문서에서 벤치마킹까지 MySQL 전체를 설치한다. "Typical"은 클라이언트와 서버 그리고 일반적으로 필요한 도구들을 설치해준다. 대부분의 사용자들에게는 "Typical"이 적당하므로 "Typical"을 선택하고 [Next] 버튼을 클릭한다.
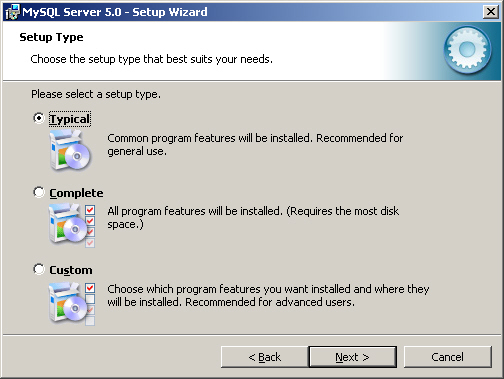
[그림 2-5] 설치 유형을 선택한다.
3. 앞서 선택했던 것을 다시 확인하고 [Install] 버튼을 클릭하면 설치가 시작된다.
[노트]
설치를 하다보면 MySQL.com 계정이 필요할 것이다. 이 계정은 여러분이 설치하고 있는 데이터베이스와는 전혀 관련이 없다. 단지 MySQL.com 웹 사이트의 계정일 뿐이다. 계정을 가지고 있지 않다면 계정을 생성해야 한다. 참고로 이런 등록 절차는 생략할 수 있다.
4. 설치가 완료되면 "MySQL Configuration Wizard"를 설치할 것인지 묻는다. 이 마법사는 반드시 설치해야 한다. 왜냐하면, 여러분의 필요에 맞게 my.ini 파일을 생성해주기 때문이다. "MySQL Configuration Wizard"를 설치하기 위해서 "Configure the MySQL Server Now" 체크 상자를 선택하자([그림 2-6] 참조).
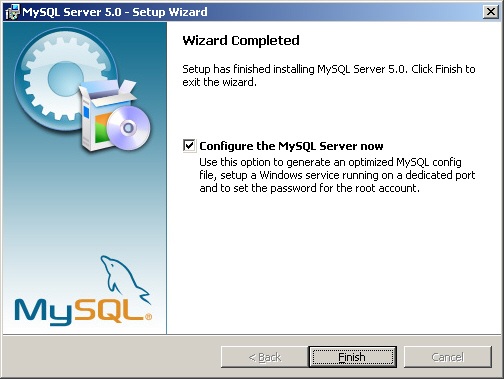
[그림 2-6] MySQL 설치 후 Configuration Wizard를 설치하는 것이 좋다.
5. "MySQL Configuration Wizard"가 실행되면 간단한 환영 메시지가 나온다. [Next] 버튼을 클릭하면 "Detailed"와 "Standard" 설치 방법 중에 하나를 선택할 수 있다. 우리는 가능한 옵션을 모두 확인하기 위해서 "Detail" 방식을 선택할 것이다. "Standard" 방식을 선택할 경우, 설정 변경을 하려면 직접 my.ini 파일을 수정해야 한다. "Detailed" 라디오 버튼을 선택하고 [Next] 버튼을 클릭한다.
6. 다음 단계는 서버 머신 타입을 결정한다. [그림 2-7]과 같이 "Developer Machine", "Server Machine", "Dedicated MySQL Server Machine"을 선택할 수 있다. 서버 머신 타입에 따라서 메모리, 디스크, 프로세서의 할당이 달라진다. 개인 컴퓨터에서 테스트 목적으로 MySQL을 설치한다면 "Developer Machine"을 선택해야 한다. 서버용 머신에서 다른 서버와 함께 MySQL을 설치하려면 "Server Machine"을 선택해야 한다. MySQL을 위한 전용 서버 머신이 준비된 경우라면 "Dedicated MySQL Server Machine"을 선택하는 것이 좋다. 이 경우 대부분의 시스템 자원을 MySQL에 할당해준다.
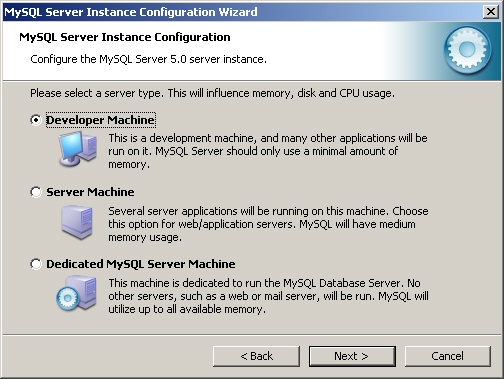
[그림 2-7] 서버 머신 타입의 설정
7. 다음 설정은 데이터베이스 사용에 대한 것이다. "Multifunctional Database"는 InnoDB와 MyISAM 엔진에 균등하게 자원을 배분한다. "Transaction Database"는 InnoDB와 MyISAM 엔진을 모두 사용할 수 있지만, InnoDB에 대부분의 자원을 할당한다. "Non-Transactional Database"는 MyISAM 엔진에 모든 자원을 할당한다. 즉, InnoDB는 사용할 수 없다. 여러분의 사용 패턴을 확신할 수 없다면 "Multifunctional Database"를 선택하는 것이 좋다.
8. InnoDB 저장 엔진이 활성화되었다면 [그림 2-8]과 같이 저장 관련 정보를 설정해야 한다. [그림 2-8]은 초기 설정 상태이다. 원한다면 설정을 바꿔도 좋다. [Next] 버튼을 클릭하면 다음 단계로 넘어간다.
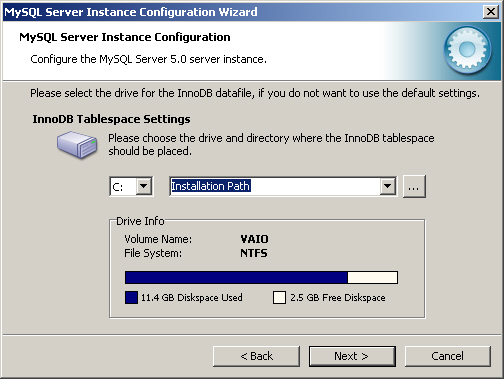
[그림 2-8] InnoDB 저장 엔진을 위한 디스크 튜닝
9. MySQL 서버의 동시 접속수를 지정한다. 동시 접속수는 데이터베이스의 사용 패턴과 트래픽 정도에 따라서 달라져야 한다. "Decision Support (DSS)/OLAP"이 기본 설정이다. 기본 설정은 최대 100개의 동시 접속을 허용하며, 평균적으로 20개의 동시 접속이 있다고 가정한다. "Online Transaction Processing(OLTP)"은 최대 500개의 동시 접속을 허용한다. "Manual Setting"은 여러분이 직접 동시 접속수를 지정할 수 있도록 해준다. 동시 접속에 대한 결정을 했다면 [Next] 버튼을 클릭한다.
10. 다음은 네트워크 옵션 설정이다. TCP/IP 사용여부와 포트를 지정할 수 있다. 기본 포트는 3306이지만, 다른 포트(사용중이지 않은 포트)로 변경할 수 있다. TCP/IP 이외에 "Enable Strict Mode" 사용여부도 지정할 수 있다. "Strict Mode"가 무엇인지 잘 모르겠다면 "Enable Strict Mode"를 선택된 상태로 두는 것이 좋다. 좀 더 자세한 정보가 필요하다면http://dev.mysql.com/doc/refman/5.0/en/server-sql-mode.html을 방문해보자. 모든 선택이 끝났다면 [Next] 버튼을 클릭한다.
[노트]
TCP/IP 설정에서 지정한 포트를 위해 방화벽 수정이 필요하다. 즉, 3306포트(직접 포트를 지정했다면 다를 수 있다)를 위한 방화벽 흐름제어가 필요하다.
11. 다음은 문자세트을 지정한다. 기본 옵션은 "Standard Character Set"으로 "Latin1"을 사용한다. "Best Support for Mulilingualism"은 UTF8을 사용한다. UTF8은 하나의 문자세트로 다국어를 표현할 수 있다. "Manual Selected Default Character Set"은 직접 문자세트를 선택할 수 있게 해준다. 이 항목을 선택하면 적당한 문자 세트를 선택할 수 있도록 드롭다운 리스트가 나온다. 설정을 마쳤으면 [Next] 버튼을 클릭한다.
12. MySQL은 서비스 형태로 설치하는 것이 좋다. [그림 2-9]는 이와 관련된 설정 화면이다. "Install As Windows Service" 체크 상자를 체크하고 서비스 이름을 선택한다. 원한다면 "Launch the MySQL Server Automatically"를 체크해도 좋다. 참고로, MySQL의 bin 폴더를 Windows PATH 환경변수에 추가하면 cmd 창에서 MySQL를 쉽게 접근할 수 있다. 설정을 마쳤으면 다음으로 넘어간다.
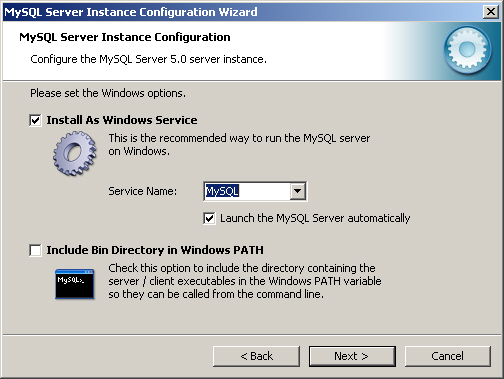
[그림 2-9] MySQL 서버 인스턴스 설정
13. 다음은 보안 옵션에 대한 설정으로 가장 중요하다. [그림 2-10]과 같이 root 암호를 지정한다. 암호를 두 번 입력하여 오타 여부를 다시 확인한다. "Enable Root Access"는 의미를 잘 알고 있는 경우에만 선택하는 것이 좋다. 일반적으로 root 접근은 로컬로 제한하는 것이 보통이다. 익명 접근을 허용할 수도 있지만 추천하지는 않는다. 보안에 좋지 않기 때문이다. 설정을 마쳤으면 [Next] 버튼을 클릭한다.
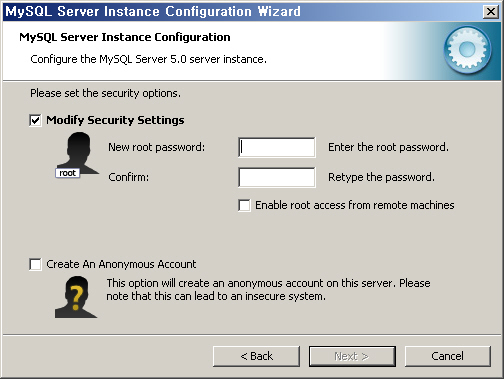
[그림 2-10] root 암호를 지정한다.
14. 이제 마지막 단계이다. [Execute] 버튼을 클릭하면 화면에 나열된 순서대로 처리를 시작한다. 모든 처리가 끝나면 [그림 2-11]과 같은 화면을 볼 수 있다.
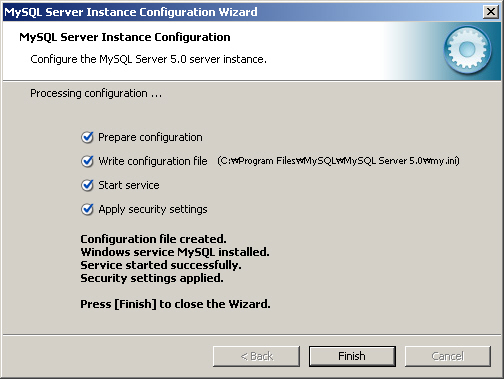
[그림 2-11] MySQL Configuration Wizard의 성공적인 종료
"MySQL Configuration Wizard"는 my.ini 설정 파일을 "C:\Program Files\MySQL\MySQL Server 5.0\"에 만들고 MySQL 서비스를 시작시켜 주는 것으로 인스톨 및 설정 과정을 마무리한다.
[팁]
my.ini 파일을 직접 수정하는 것도 가능하다. 수정 후에는 반드시 MySQL 서버를 다시 시작해야 한다.
Introduction
MySQL Cluster Overview

Basic MySQL Cluster Concepts
- MGM node : 이 노드는 설정을 포함, 다른 노드를 관리하는 매니저 노드이다. 다른 노드보다 가장 먼저 실행되며 ndb_mgmd 명령으로 실행시킨다.
- data node : 클러스터의 데이터를 저장하는 노드이다. ndbd 명령으로 실행시킨다.
- SQL node : 클러스터 데이터에 접근하는 노드이다. MySQL 클러스터에서는 NDB 클러스터 스토리지 엔진을 사용하는 MySQL 서버가 클라이언트 노드이다. mysqld --ndbcluster나 mysqld 명령으로 실행시키는데, 이 때는 my.cnf 에 ndbcluster를 추가한다.
Simple Multi-Computer How-To

# cd /usr/local # groupadd mysql # useradd -g mysql mysql
# tar -xzvf mysql-max-4.1.13-pc-linux-gnu-i686.tar.gz # ln -s /usr/local/ mysql-max-4.1.13-pc-linux-gnu-i686 mysql
# cd mysql # scripts/mysql_install_db --user=mysql
# chown -R root . # chown -R mysql data # chgrp -R mysql .
# cp support-files/mysql.server /etc/rc.d/init.d/ # chmod +x /etc/rc.d/init.d/mysql.server # chkconfig --add mysql.server
# cd /usr/local/mysql/bin/ # cp ndb_mgm* /usr/local/bin/ # chmod +x ndb_mgm*
# vi /etc/my.cnf [MYSQLD] # Options for mysqld process: Ndbcluster # run NDB engine ndb-connectstring=192.168.0.10 # location of MGM node [MYSQL_CLUSTER] # Options for ndbd process: ndb-connectstring=192.168.0.10 # location of MGM node
# mkdir /var/lib/mysql-cluster
# cd /var/lib/mysql-cluster
# vi config.ini
[NDBD DEFAULT] # Options affecting ndbd processes on all data nodes:
NoOfReplicas=2 # Number of replicas
DataMemory=80M # How much memory to allocate for data storage
IndexMemory=18M # How much memory to allocate for index storage
# For DataMemory and IndexMemory, we have used the
# default values. Since the "world" database takes up
# only about 500KB, this should be more than enough
# for this example Cluster setup.
[TCP DEFAULT] # TCP/IP options:
portnumber=2202 # This the default; however, you can use any
# port that is free for all the hosts in cluster
# Note: In MySQL 5.0, this parameter is deprecated;
# it is recommended that you do not specify the
# portnumber at all and simply allow the port to be
# allocated automatically
[NDB_MGMD] # Management process options:
hostname=192.168.0.10 # Hostname or IP address of MGM node
datadir=/var/lib/mysql-cluster # Directory for MGM node logfiles
[NDBD] # Options for data node "A":
# (one [NDBD] section per data node)
hostname=192.168.0.30 # Hostname or IP address
datadir=/usr/local/mysql/data # Directory for this data node's
# datafiles
[NDBD] # Options for data node "B":
hostname=192.168.0.40 # Hostname or IP address
datadir=/usr/local/mysql/data # Directory for this data node's
# datafiles
[MYSQLD] # SQL node options:
hostname=192.168.0.20 # Hostname or IP address
datadir=/usr/local/mysql/data # Directory for SQL node's datafiles
# (additional mysqld connections can be
# specified for this node for various
# purposes such as running ndb_restore)
# ndb_mgmd -f /var/lib/mysql-cluster/config.iniMGM 노드를 다운시킬 때에는 다음과 같이 하면 된다.
# ndb_mgm -e shutdown
# ndbd --initial
# /etc/rc.d/init.d/mysql.server start
# ndb_mgm -- NDB Cluster -- Management Client -- ndb_mgm>
ndb_mgm> show Connected to Management Server at: 192.168.0.10:1186 Cluster Configuration --------------------- [ndbd(NDB)] 2 node(s) id=2 @192.168.0.30 (Version: 4.1.13, Nodegroup: 0, Master) id=3 @192.168.0.40 (Version: 4.1.13, Nodegroup: 0) [ndb_mgmd(MGM)] 1 node(s) id=1 @192.168.0.10 (Version: 4.1.13) [mysqld(API)] 1 node(s) id=4 (Version: 4.1.13) ndb_mgm>
MySQL 클러스터의 제한
- 트랙잭션 수행 중의 롤백을 지원하지 않으므로, 작업 수행 중에 문제가 발생하였다면, 전체 트랙잭션 이전으로 롤백하여야 한다.
- 실제 논리적인 메모리의 한계는 없으므로 물리적으로 허용하는 만큼 메모리를 설정하는 것이 가능하다.
- 컬럼 명의 길이는 31자, 데이터베이스와 테이블 명은 122자까지 길이가 제한된다. 데이터베이스 테이블, 시스템 테이블, BLOB인덱스를 포함한 메타 데이터(속성정보)는 1600개까지만 가능하다.
- 클러스터에서 생성할 수 있는 테이블 수는 최대 128개이다.
- 하나의 로우 전체 크기가 8KB가 최대이다(BLOB를 포함하지 않은 경우).
- 테이블의 Key는 32개가 최대이다.
- 모든 클러스터의 기종은 동일해야 한다. 기종에 따른 비트저장방식이 다른 경우에 문제가 발생하기 때문이다.
- 운영 중 스키마 변경이 불가능하다.
- 운영 중 노드를 추가하거나 삭제할 수 없다.
- 최대 데이터 노드의 수는 48개이다.
- 모든 노드는 63개가 최대이다. (SQL node, Data node, 매니저를 포함)
MySQL Cluster FAQ
5. MySQL Cluster Glossary
- ndbd : 데이터 노드 데몬
- ndb_mgmd : MGM서버 데몬
- ndb_mgm : MGM 클라이언트
- ndb_waiter : 클러스터의 모든 노드들의 상태를 확인할 때 사용
- ndb_restore : 백업으로부터 클러스터의 데이터를 복구할 때 사용
Dual-Master Replication in MySQL
![[-]](http://wiki.kldp.org/imgs/plugin/arrup.png "[-]")
1.1 Replication 이란?
1.2.1 MASTER 와 SLAVE 설치
1.2.2 MASTER 계정생성
master mysql > GRANT REPLICATION SLAVE ON *.*
-> TO 'user_name'@'user_host' IDENTIFIED BY 'user_password';
master mysql > GRANT FILE ON *.*
-> TO 'user_name'@'user_host' IDENTIFIED BY 'user_password';
1.2.3 MASTER 데이터 SLAVE 에 복사
master mysql > FLUSH TABLES WITH READ LOCK; master shell > tar -cvf /tmp/mysql-snapshot.tar . slave shell > tar -xvf /tmp/mysql-snapshot.tar master mysql > UNLOCK TABLES;
master Shell > mysqldump -u root -p ‘password’ -B db_name > dump_file.sql
1.2.4 MASTER 환경설정
master shell> vi /etc/my.cnf
[mysqld] log-bin server-id = 1
1.2.5 SLAVE 환경설정
slave shell> vi /etc/my.cnf
[mysqld] server-id = 2 master-host = xxx.xxx.xxx.xxx(user_host) master-port = 3306 master-user = user_name master-password = user_password
1.2.7 SLAVE 덤프파일 LOAD
slave shell > mysql -u root -p < dump_file.sql
1.2.8 MASTER 계정 설정
slave mysql > CHANGE MASTER TO
-> MASTER_HOST='master_host_name',
-> MASTER_USER='replication_user_name',
-> MASTER_PASSWORD='replication_password',
-> MASTER_LOG_FILE='recorded_log_file_name',
-> MASTER_LOG_POS=recorded_log_position;
MASTER_HOST 60 MASTER_USER 16 MASTER_PASSWORD 32 MASTER_LOG_FILE 255
1.2.10 SUCCESS CERTIFICATION
Slave I/O thread: connected to master 'user_name@user_host:3306', replication started in log 'FIRST' at position 4
1.3 How to Set Up Dual-Master Replication
1.3.4 GRANT REPLICATION SLAVE
mysql2 mysql > GRANT REPLICATION SLAVE ON *.*
-> TO 'users_name'@'users_host' IDENTIFIED BY 'users_password';
1.3.5 MASTER SETUP
mysql1 shell > /etc/init.d/mysqld stop
1.3.6 MASTER CONFIGURATION
[mysqld] server-id = 1 <= 그대로 두고, 아래 내용을 추가한다. master-host = users_host master-port = 3306 master-user = users_name master-password = users_password
1.3.8 SUCCESS CERTIFICATION
Slave I/O thread: connected to master 'ccotti@222.112.137.172:3306', replication started in log 'FIRST' at position 4
1.4 장애복구
mysql1 shell > /etc/init.d/mysqld start
mysql2 mysql > slave stop; mysql2 mysql > slave reset; mysql2 mysql > slave start;
1.5 참고
SQL(Structured Query Language)의 가장 큰 특징 중의 하나는 여러개의 테이블을
연결시켜 데이터를 검색하거나 조작할 수 있는 기능이다. 이것은 데이터를 쉽고
빠르게 검색하고 불필요한 데이터를 줄여주는 장점이 있다. 다른 SQL 언어와 마찬
가지로 MySQL도 join명령어로 이 연산을 수행한다.
간단히 말하면 join은 두개 이상의 테이블로부터 필요한 데이터를 연결해 하나의
포괄적인 구조로 결합시키는 연산이다.
예를 들어, 한 컴퓨터 제조업자가 자신의 데이터를 능률적으로 관리하기 위한
데이터베이스가 필요하다고 하자. 이 데이터들은 주문, 고객, 생산과 같은 어떤
일관성있는 개념과 관련된 각각의 데이터들이 모여 다양하고 간결한 테이블들을
이룰 것이다. 테이블을 생성한 후에는, 다양한 예를 들어 데이터베이스에서 가장
많이 사용되는 join의 조작법에 대해 설명하겠다.
첫번째 테이블은 제조업자가 분류한 다양한 타입의 PC들의 데이터로 구성될 것이다.
----------------------------------------------
mysql> create table pcs (
-> pid INT, // product id
-> spec char(3),
-> os char(10),
-> ram INT,
-> hd char(4)
-> );
-----------------------------------------------
두번째 테이블은 제조업자의 다양한 고객들에 관한 데이터로 이루어질 것이다.
-----------------------------------------------
mysql> create table clients (
-> name char(25),
-> cid char(8), // client id
-> email char(25),
-> tel char(10)
-> );
-----------------------------------------------
세번째 테이블은 주문 정보에 관한 데이타를 포함할 것이다.
-----------------------------------------------
mysql> create table orders (
-> order_date date,
-> pid INT,
-> cid char(8)
-> );
-----------------------------------------------
◆◆ 자료(Data) 삽입하기
각각의 테이블에 아래와 같이 자료를 삽입해 보자.
☆ pcs (테이블1)
+------+------+-------+------+------+
| pid | spec | os | ram | hd |
+------+------+-------+------+------+
| 1 | 386 | Linux | 64 | 3.1 |
| 2 | 386 | Linux | 128 | 4.2 |
| 3 | 486 | WinNT | 64 | 3.1 |
| 4 | 586 | Linux | 128 | 4.2 |
| 5 | 586 | Win98 | 128 | 6.4 |
+------+------+-------+------+------+
[삽입방법]
-----------------------------------------------------------
mysql> INSERT INTO pcs (pid, spec, os, ram, hd)
-> VALUES (1, '386', 'Linux', 64, '3.1');
-----------------------------------------------------------
☆ clients (테이블2)
+--------+---------+---------------------------+------------+
| name | cid | email | tel |
+--------+---------+---------------------------+------------+
| 원주희 | wjh-042 | haremoon at won.hongik.ac.kr | 123-456-78 |
| 홍길동 | hgd-043 | honggd at won.hongik.ac.kr | 421-555-34 |
| 이쁘니 | pty-042 | pretty at won.hongik.ac.kr | 459-555-32 |
| 못난이 | ugy-043 | ugly at won.hongik.ac.kr | 439-555-88 |
+--------+---------+---------------------------+------------+
[삽입방법]
-----------------------------------------------------------
mysql> INSERT INTO clients (name, cid, email, tel)
-> VALUES ('원주희', 'wjh-042',
-> 'haremoon at won.hongik.ac.kr', '123-456-7890');
-----------------------------------------------------------
☆ orders (테이블3)
+------------+------+---------+
| order_date | pid | cid |
+------------+------+---------+
| 1999-12-05 | 2 | wjh-042 |
| 1999-12-04 | 3 | hgd-043 |
| 1999-12-04 | 1 | wjh-042 |
| 1999-12-05 | 2 | wjh-042 |
| 1999-12-12 | 5 | ugy-043 |
| 1999-12-05 | 5 | pty-042 |
+------------+------+---------+
[삽입방법]
-----------------------------------------------------------
mysql> INSERT INTO orders (order_date, pid, cid)
-> VALUES ('1999-12-05', 2, 'wjh-042');
-----------------------------------------------------------
자, 이제부터 만들어진 3개의 테이블로부터 필요한 데이터만을 추출해 결합하는
방법에 대해 알아보자. 만일 당신의 상사가 특정한 날에 특정한 PC를 주문한 모든
고객의 이메일 목록을 원한다고 하자! 또는 특정한 고객에 의해 작성된 주문서에
있는 RAM의 양을 보고받기를 원한다고 하자. 이러한 모든 일들은 다양한 join문에
의해 쉽게 수행될 수 있다. 만들어진 테이블을 사용해 첫번째 join문을 생성해보고
작성해보자.
◆◆ The Cross Join
Cross Join은 가장 기본적인 join의 타입으로 한 테이블에 있는 각각의 열이 다른
테이블의 모든 열에 간단하게 매치되어 출력된다. 능률적이지는 않지만, 모든 join
의 공통된 특징을 나타내준다.
Cross Join의 간단한 예 :
----------------------------------------------
mysql> SELECT * FROM pcs, clients;
----------------------------------------------
매우 많은 열들이 출력될 것이다. 테이블1(pcs)에 있는 각각의 열이
테이블2(clients)
의 모든 열에 매치된다는 것을 기억하자. 따라서, 3 열을 가진 테이블1(pcs)과 4
열을
가진 테이블2(clients)를 포함한 join문은 총 12 열의 테이블을 만들것이다.
즉 cross-join은 테이블1에 있는 각각의 열들이 테이블2에 있는 모든열들을 한 번씩
교차해 출력한다고 기억하는 것이 쉬울 것같다.
첫번째 join을 성공적으로 수행했다면 다음의 예도 어렵지 않을 것이다.
아래의 예를 따라해 보고 어떤 결과가 출력될지 예상해보자.
-----------------------------------------------------------------------------
mysql> select c.name, o.cid from orders o, clients c where o.cid = "wjh-042";
-----------------------------------------------------------------------------
+--------+---------+
| name | cid |
+--------+---------+
| 원주희 | wjh-042 |
| 원주희 | wjh-042 |
| 원주희 | wjh-042 |
| 홍길동 | wjh-042 |
| 홍길동 | wjh-042 |
| 홍길동 | wjh-042 |
| 이쁘니 | wjh-042 |
| 이쁘니 | wjh-042 |
| 이쁘니 | wjh-042 |
| 못난이 | wjh-042 |
| 못난이 | wjh-042 |
| 못난이 | wjh-042 |
+--------+---------+
예상한 대로 결과가 출력되었나? clients 테이블에 있는 각각의 name이 orders테이
블의 "wjh-042"를 포함한 열마다 매치되어 출력되었다. 지금까지의 설명이 Cross
Join을 설명하는데 충분하지 않으므로 다른 질의를 사용해가며 JOIN을 활용해보기
바란다.
NOTE : 왜 테이블의 이름에 별명을 주어 사용할까? Aliases(별명)은 질의를 입력할
때 반복적인 키의 입력을 줄여주는 방법으로 사용되어진다. 따라서 열을 지정해 줄
때 반복적으로 'clients'를 한자 한자 입력하는 대신에, 질의내에 'from clients c'
를 지정해주고 'c'를 사용할 수 있다.
Cross Join이 테이블들을 연결해 주기는 하지만, 능률적이지는 못하다. 따라서
각각의 테이블들로 부터 우리가 원하는 데이타를 어떻게 하면 쉽게 선택할 수 있는지
계속 다음 장을 읽어보기 바란다.
◆◆ The Equi-join
Equi-join은 한 테이블에 있는 어떠한 값이 두번째(또는 다수의) 테이블내에 포함된
값에 일치 할 때 수행된다.
product id 가 1인 PC를 주문한 고객의 목록을 원한다고 가정해 보자.
-------------------------------------------------------------------
mysql> select p.os, c.name from orders o, pcs p, clients c
-> where p.pid=o.pid and o.pid = 1 and o.cid=c.cid;
-------------------------------------------------------------------
+-------+--------+
| os | name |
+-------+--------+
| Linux | 원주희 |
+-------+--------+
◆ Non-Equi-join
Equi-join은 다수의 테이블들 사이에서 일치하는 자료들만을 추출해낸다. 그러나
만일 일치하지 않은 자료들만을 추출해야 한다면...? 예를 들어, 당신의 상사가
주문한 pid가 제품의 pid보다 더 큰 order id의 모든 운영체제(OS)의 목록을
필요로 한다면 어떻게 할 것인가? 적당히 이름을 non-equi join라고 하겠다.
-------------------------------------------------------------------
mysql> SELECT p.os, o.pid from orders o, pcs p where o.pid > p.pid;
-------------------------------------------------------------------
+-------+------+
| os | pid |
+-------+------+
| Linux | 2 |
| Linux | 3 |
| Linux | 2 |
| Linux | 5 |
| Linux | 5 |
| Linux | 3 |
| Linux | 5 |
| Linux | 5 |
| WinNT | 5 |
| WinNT | 5 |
| Linux | 5 |
| Linux | 5 |
+-------+------+
orders 테이블의 pid가 pcs테이블의 pid보다 더 큰 모든 열들이 매치될 것이다.
주의깊게 살펴보면, 여러가지 제한을 준 간단한 cross-join 임을 파악할 수 있
을 것이다. 상사에게는 특별하게 유용하지 않을 지도 모르지만, 매우 유용한 기
능인 left join을 위한 준비 과정으로 생각하자. 자, 이제 다음장으로 가서
left join을 사용할 때 유용할 수있는 옵션들에 대해 집중적으로 알아보자.
◆◆ The Left Join
Left Join은 사용자가 어떠한 제한을 기반으로 관심있는 모든 종류의 자료를 추출
하게한다. 테이블 join중 가장 막강한 옵션으로, 테이블을 매우 쉽게 조작할 수
있게 한다.
만일 상사가 좀더 자세히, 자세히, 자세하게, 자세하게!를 외친다고 가정해보자.
left join이 우리의 문제를 해결해 줄 것이다.
-------------------------------------------------------------------
mysql> select * from orders left join pcs on orders.pid = pcs.pid;
-------------------------------------------------------------------
+------------+------+---------+------+------+-------+------+------+
| order_date | pid | cid | pid | spec | os | ram | hd |
+------------+------+---------+------+------+-------+------+------+
| 1999-12-05 | 2 | wjh-042 | 2 | 386 | Linux | 128 | 4.2 |
| 1999-12-04 | 3 | hgd-043 | 3 | 486 | WinNT | 64 | 3.1 |
| 1999-12-04 | 1 | wjh-042 | 1 | 386 | Linux | 64 | 3.1 |
| 1999-12-05 | 2 | wjh-042 | 2 | 386 | Linux | 128 | 4.2 |
| 1999-12-12 | 5 | ugy-043 | 5 | 586 | Win98 | 128 | 6.4 |
| 1999-12-05 | 5 | pty-042 | 5 | 586 | Win98 | 128 | 6.4 |
+------------+------+---------+------+------+-------+------+------+
고객이 주문한 모든 PC들의 목록을 추출해 낸다. 예를 들어, PHP3 또는 Perl
스크립트를 사용해 영수증을 출력하는데 사용할 수도 있다. 고객들에게 우리회
사로부터 구입한 모든 제품의 목록을 가끔씩 메일로 보내야 할 때에도
clients 테이블과 연결해 사용할 수 있을 것이다.
아래의 예에서 우리는 제품의 id(pid)가 3인 PC의 정보만을 볼 수 있다.
-------------------------------------------------------------------
mysql> select * from orders left join pcs on pcs.pid=3 and pcs.pid=orders.pid;
-------------------------------------------------------------------
+------------+------+---------+------+------+-------+------+------+
| order_date | pid | cid | pid | spec | os | ram | hd |
+------------+------+---------+------+------+-------+------+------+
| 1999-12-05 | 2 | wjh-042 | NULL | NULL | NULL | NULL | NULL |
| 1999-12-04 | 3 | hgd-043 | 3 | 486 | WinNT | 64 | 3.1 |
| 1999-12-04 | 1 | wjh-042 | NULL | NULL | NULL | NULL | NULL |
| 1999-12-05 | 2 | wjh-042 | NULL | NULL | NULL | NULL | NULL |
| 1999-12-12 | 5 | ugy-043 | NULL | NULL | NULL | NULL | NULL |
| 1999-12-05 | 5 | pty-042 | NULL | NULL | NULL | NULL | NULL |
+------------+------+---------+------+------+-------+------+------+
◆ The Using Clause
left join에 약간의 옵션을 주어 둘 이상의 테이블에 있는 동일한 컬럼을 조금 더
깊게 연관지을수도 있다. on과 using옵션이 사용되며, 아래의 예제를 참조하자.
--------------------------------------------------------------------
## 원본의 예제는 아래와 같지만, 에러가 발생해 필자가 MySQL매뉴얼을 참조해
나름대로 수정을 했다.##
mysql> SELECT * from clients join on orders where clients.cid = orders.cid;
mysql> SELECT * from clients join on orders using (cid);
-------------------------------------------------------------------
==> 수정한 예제
-------------------------------------------------------------------
mysql> SELECT * from clients left join orders on clients.cid = orders.cid;
-------------------------------------------------------------------
또는 아래와 같이 나타낼 수도 있다.
-------------------------------------------------------------------
mysql> SELECT * from clients left join orders using (cid);
-------------------------------------------------------------------
두 예제 모두 똑같은 결과가 출력될 것이다.
+--------+---------+---------------------------+------------+------------+------+---------+
| name | cid | email | tel | order_date | pid |
cid |
+--------+---------+---------------------------+------------+------------+------+---------+
| 원주희 | wjh-042 | haremoon at won.hongik.ac.kr | 123-456-78 | 1999-12-05 | 2 |
wjh-042 |
| 원주희 | wjh-042 | haremoon at won.hongik.ac.kr | 123-456-78 | 1999-12-04 | 1
| wjh-042 |
| 원주희 | wjh-042 | haremoon at won.hongik.ac.kr | 123-456-78 | 1999-12-05 | 2
| wjh-042 |
| 홍길동 | hgd-043 | honggd at won.hongik.ac.kr | 421-555-34 | 1999-12-04 | 3
| hgd-043 |
| 이쁘니 | pty-042 | pretty at won.hongik.ac.kr | 459-555-32 | 1999-12-05 | 5
| pty-042 |
| 못난이 | ugy-043 | ugly at won.hongik.ac.kr | 439-555-88 | 1999-12-12 | 5
| ugy-043 |
+--------+---------+---------------------------+------------+------------+------+---------+
다른 구문의 예를 적용해 가며 left join에 대해 이해하기 바란다. 공부를 하다보면
left join이 여러분의 개발활동에 매우 중요한 역할을 한 다는 것을 느낄 것이다.
테이블 join에 관한 정보를 좀더 깊게 교환하고 싶다면 http://www.mysql.com에 있는
다양한 토론 그룹을 체크해 보기 바란다.
◆◆ Self-joins
Self-join은 관리자가 하나의 테이블에 관련된 데이타를 집중시키는 막강한 방법을
제공해 준다. 사실, self-join은 그 자신의 테이블에 결합하는 것에 의해 수행된다.
개념의 이해를 위해 예를 들어 설명하겠다.
컴퓨터 워크스테이션을 만드는데 사용되는 하드웨어의 다양한 부품에 관한 정보를
가진 매우 큰 데이타베이스를 관리해야 한다고 가정하자. 워크스테이션은 데스크,
PC, 모니터, 키보드, 마우스등으로 이루어져 있다. 게다가, 데스크는 워크스테이션의
모두 다른 부분의 '부모'라고 생각될 수 있다. 우리는 각 워크스테이션의 레코드가
정확한 자료로 유지되기를 원할 것이며, 유일한 ID번호를 부여함으로써 워크스테이션
의 모든 부분을 구체적으로 관련시킬 것이다. 사실, 각 부분은 항목을 분명하게
해주는
유일한 ID번호와 그것의 부모(데스크) ID번호를 확인하기 위한, 두개의 ID 번호를
포함 것이다.
테이블이 아래와 같다고 가정하자.
mysql> select * from ws;
+---------+-----------+-----------+
| uniq_id | name | parent_id |
+---------+-----------+-----------+
| d001 | desktop | NULL |
| m4gg | monitor | d001 |
| k235 | keyboar | d001 |
| pc345 | 200mhz pc | d001 |
| d002 | desktop | NULL |
| m156 | monitor | d002 |
| k9334 | keyboar | d002 |
| pa556 | 350mhz pc | d002 |
+---------+-----------+-----------+
desktop은 그와 관련된 모든 부분들의 부모와 같으므로 parent_id를 가지고 있지
않음을 주목하자. 지금부터 유용한 정보를 위한 질의를 시작할 것이다. self-join
의 사용법을 쉽게 설명하기 위해 테이블을 간단하게 만들었다.
-------------------------------------------------------------------
mysql> select t1.*, t2.* from ws as t1, ws as t2;
-------------------------------------------------------------------
어떻게 출력되는가? 이전처럼, 첫번째 테이블의 각 열들이 두번째 테이블에 있는
모든 열들에 매치되어 연결되 출력될 것이다. 우리에게 매우 유용하지는 않지만
다시 한번 시도해보고 확인해 보기바란다. 좀더 재미있는 예를 들어보겠다.
-------------------------------------------------------------------
mysql> select parent.uniq_id, parent.name, child.uniq_id, child.name
-> from ws as parent, ws as child
-> where child.parent_id = parent.uniq_id and parent.uniq_id = "d001";
-------------------------------------------------------------------
흥미로운 결과가 출력될 것이다.
+---------+---------+---------+-----------+
| uniq_id | name | uniq_id | name |
+---------+---------+---------+-----------+
| d001 | desktop | m4gg | monitor |
| d001 | desktop | k235 | keyboar |
| d001 | desktop | pc345 | 200mhz pc |
+---------+---------+---------+-----------+
self-join은 테이블의 자료를 검증하는 방법으로도 사용된다. 테이블내에 있는
uniq_id컬럼은 테이블에서 유일해야 하며, 만일 데이타의 엔트리가 깊어 뜻하지
않게 같은 uniq_id를 가진 두개의 항목이 데이타베이스에 입력된다면 좋지 않은
결과가 생길것이다. 이럴 경우 정기적으로 self-join을 사용해 체크할 수 있다.
우리는 350mhz pc의 uniq_id가 'm156'(이 값은 워크스테이션 'd002'에 속한
모니터의 uniq_id 값이다.)이 되도록 변경했다고 가정하자.
테이블의 내용은 다음과 같이 변경한다.
-------------------------------------------------------------------
mysql> update ws set uniq_id = 'm156' where name = '350mhz pc';
-------------------------------------------------------------------
아래의 예를 참고해 ws테이블에 self-join을 적용해보자.
-------------------------------------------------------------------
mysql> select parent.uniq_id, parent.name, child.uniq_id, child.name
-> from ws as parent, ws as child
-> where parent.uniq_id = child.uniq_id and parent.name <> child.name;
-------------------------------------------------------------------
아래와 같이 출력될 것이다.
+---------+-----------+---------+-----------+
| uniq_id | name | uniq_id | name |
+---------+-----------+---------+-----------+
| m156 | 350mhz pc | m156 | monitor |
| m156 | monitor | m156 | 350mhz pc |
+---------+-----------+---------+-----------+
Table join은 데이터베이의 관리를 쉽게 도와줄것이다. 구문의 이해를 정확하게
하기위해서 예제에서 배운 명령을 다양하게 변화시켜 적용해보기 바란다.
---- MySQL_Tables_Joins.txt 내용 --------------------------
-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-
원본사이트: http://www.devshed.com/Server_Side/MySQL/Join/
* MySQL Table Joins
*(o) By W.J. Gilmore
*(o)| July 06, 1999
(o)| | 번역 : 원주희(lolol@shinan.hongik.ac.kr)
=======================================================================
[영어실력이 너무 부족하다보니 잘못된 부분이 있을 수도 있습니다.
고쳐야할 부분이 있으면 꼭 메일을 보내주세요.]
◆◆ 소개하기
SQL(Structured Query Language)의 가장 큰 특징 중의 하나는 여러개의 테이블을
연결시켜 데이터를 검색하거나 조작할 수 있는 기능이다. 이것은 데이터를 쉽고
빠르게 검색하고 불필요한 데이터를 줄여주는 장점이 있다. 다른 SQL 언어와 마찬
가지로 MySQL도 join명령어로 이 연산을 수행한다.
간단히 말하면 join은 두개 이상의 테이블로부터 필요한 데이터를 연결해 하나의
포괄적인 구조로 결합시키는 연산이다.
예를 들어, 한 컴퓨터 제조업자가 자신의 데이터를 능률적으로 관리하기 위한
데이터베이스가 필요하다고 하자. 이 데이터들은
......생략
원본 : http://database.sarang.net/?inc=read&aid=24199&criteria=mysql&subcrit=&id=&limit=20&keyword=explain&page=1
# 이글은 mysql document 의 7.2.1 Explain Syntax 를 대~충 번역한 것입니다.
# 틈틈이 번역하고 있으나 언제 완료될지 모릅니다..
EXPLAIN 을 사용함으로써 인덱스가 적절히 사용되고 있는지 검토할 수 있다. 인덱스가 잘못 사용되고 있다면 ANALYZE TABLE 을 사용하여 테이블을 점검하라.
이것은 테이블의 상태를 갱신하며 옵티마이저의 동작에 영향을 준다.
옵티마이저가 SELECT 에 기록된 순서대로 조인을 행하게 강제하려면 SELECT 대신에 SELECT STRAIGHT_JOIN 을 사용하라.
EXPLAIN 은 SELECT 문에 사용된 각 테이블당 하나의 행을 리턴한다. 나열된 순서는 MYSQL 이 쿼리처리에 사용하는 순서대로 출력된다.
MYSQL 은 모든 조인을 single-sweep multi-join 방식을 사용하여 해결한다. 이것은 MYSQL 이 첫번째 테이블에서 한행을 읽고, 두번째 테이블에서 매치되는 행을 찾고, 세번째 테이블에서 매치되는 행을 찾고.. 그러한 방식이다. 모든 테이블들이 처리된 후 추출된 컬럼을 출력하고 다시 처음 테이블로 돌아가서 조인을 계속한다. 이런식으로 첫번째 테이블에 더이상 남는행이 없을때까지 실행한다.
(어느것이 첫번째 테이블이 될지는 mysql 옵티마이저가 결정할 문제이다. STRAIGHT_JOIN 을 명시하지 않았다면 유저가 입력한 순서와는 관련이 없다.)
MYSQL 4.1 버전에서 EXPLAIN 의 출력포멧이 UNION 과 subquery, derived table 을 다루기에 더 효과적으로 변경되었다. 무엇보다 중요한 것은 id , select_type 의 두 컬럼이 추가된 것이다.
EXPLAIN 의 각 행은 하나의 테이블에 대한 정보를 보여주며 다음과 같은 컬럼들로 구성된다.
idSELECT 번호, 쿼리내의 SELECT 의 구분번호이다.
select_typeSELECT 의 타입, 다음과 같다.
SIMPLE단순 SELECT (UNION 이나 서브쿼리를 사용하지 않음)
PRIMARY가장 외곽의 SELECT
UNIONUNION 에서의 두번째 혹은 나중에 따라오는 SELECT
DEPENDENT UNIONUNION 에서의 두번째 혹은 나중에 따라오는 SELECT, 외곽쿼리에 의존적이다.
UNION RESULTUNION 의 결과물.
SUBQUERY서브쿼리의 첫번째 SELECT
DEPENDENT SUBQUERY서브쿼리의 첫번째 SELECT, 외곽쿼리에 의존적이다.
DERIVEDSELECT 로 추출된 테이블 (FROM 절 내부의 서브쿼리)
table나타난 결과가 참조하는 테이블명.
type조인타입, 아래와 같다. 우수한 순서대로 뒤로갈수록 나쁜 조인형태이다.
system테이블에 단 하나의 행만 존재(시스템 테이블). const join 의 특수한 경우이다.
const많아야 하나의 매치되는 행만 존재하는 경우. 하나의 행이기 때문에 각 컬럼값은 나머지 연산에서 상수로 간주되며, 처음 한번만 읽어들이면 되기 때문에 무지 빠르다.
PRIMARY KEY 나UNIQUEindex 를 상수와 비교하는 경우.
아래의 경우에서 tbl_name 은 const table 로 조인된다.
SELECT * FROMtbl_nameWHEREprimary_key=1;
SELECT * FROMtbl_name
WHEREprimary_key_part1=1 ANDprimary_key_part2=2;
eq_ref조인수행을 위해 각 테이블에서 하나씩의 행만이 읽혀지는 형태. const 타입이외에 가장 훌륭한 조인타입니다.
조인연산에 PRIMARY KEY 나UNIQUEindex 인덱스가 사용되는 경우.
인덱스된 컬럼이 = 연산에 사용되는 경우. 비교되는 값은 상수이거나 이전조인결과의 컬럼값일수 있다.
다음 예에서 MySQL 은 ref_table 을 처리하는데 eq_ref 조인을 사용한다.
SELECT * FROMref_table,other_table
WHEREref_table.key_column=other_table.column;
SELECT * FROMref_table,other_table
WHEREref_table.key_column_part1=other_table.column
ANDref_table.key_column_part2=1;
ref이전 테이블과의 조인에 사용될 매치되는 인덱스의 모든행이 이 테이블에서 읽혀진다. leftmost prefix 키만을 사용하거나 사용된 키가 PRIMARY KEY 나
UNIQUE가 아닐때(즉 키값으로 단일행을 추출할수 없을때) 사용되는 조인.
만약 사용된 키가 적은수의 행과 매치될때 이것은 적절한 조인 타입니다.
ref 는 인덱스된 컬럼과 = 연산에서 사용된다.
아래 예에서 MySQL 은 ref_table 처리에 ref 조인 타입을 사용한다.
SELECT * FROMref_tableWHEREkey_column=expr;
SELECT * FROMref_table,other_table
WHEREref_table.key_column=other_table.column;
SELECT * FROMref_table,other_table
WHEREref_table.key_column_part1=other_table.column
ANDref_table.key_column_part2=1;
ref_or_nullref 와 같지만 NULL 값을 포함하는 행에대한 검색이 수반된다.
4.1.1 에서 새롭게 도입된 조인타입이며 서브쿼리 처리에서 대개 사용된다.
아래 예에서 MySQL 은 ref_table 처리에 ref_or_null 조인타입을 사용한다.SELECT * FROM
ref_tableWHEREkey_column=exprORkey_columnIS NULL;index_merge인덱스 병합 최적화가 적용되는 조인 타입.
이 경우, key 컬럼은 사용된 인덱스의 리스트를 나타내며 key_len 컬럼은 사용된 인덱스중 가장 긴 key 명을 나타낸다.
For more information, see Section 7.2.6, “Index Merge Optimization”.
unique_subquery이것은 아래와 같은 몇몇 IN 서브쿼리 처리에서 ref 타입대신 사용된다.
valueprimary_keyFROMsingle_tableWHEREsome_expr)
unique_subquery 는 성능향상을 위해 서브쿼리를 단순 index 검색 함수로 대체한다.
index_subqueryunique_subquery 와 마찬가지로 IN 서브쿼리를 대체한다. 그러나 이것은 아래와 같이 서브쿼리에서 non-unique 인덱스가 사용될때 동작한다.
valuekey_columnFROMsingle_tableWHEREsome_expr)
range인덱스를 사용하여 주어진 범위 내의 행들만 추출된다. key 컬럼은 사용된 인덱스를 나타내고 key_len 는 사용된 가장 긴 key 부분을 나타낸다.
ref 컬럼은 이 타입의 조인에서 NULL 이다.
range 타입은 키 컬럼이 상수와=,<>,>,>=,<,<=,IS NULL,<=>,BETWEEN 또는IN연산에 사용될때 적용된다.
SELECT * FROM
tbl_nameWHEREkey_column= 10; SELECT * FROMtbl_nameWHEREkey_columnBETWEEN 10 and 20; SELECT * FROMtbl_nameWHEREkey_columnIN (10,20,30); SELECT * FROMtbl_nameWHEREkey_part1= 10 ANDkey_part2IN (10,20,30);
index이 타입은 인덱스가 스캔된다는걸 제외하면 ALL 과 같다. 일반적으로 인덱스 파일이 데이타파일보다 작기 때문에 ALL 보다는 빠르다.
MySQL 은 쿼리에서 단일 인덱스의 일부분인 컬럼을 사용할때 이 조인타입을 적용한다.
ALL이전 테이블과의 조인을 위해 풀스캔이 된다. 만약 (조인에 쓰인) 첫번째 테이블이 고정이 아니라면 비효율적이다, 그리고 대부분의 경우에 아주 느린 성능을 보인다. 보통 상수값이나 상수인 컬럼값으로 row를 추출하도록 인덱스를 추가함으로써 ALL 타입을 피할 수 있다.
possible_keys이 컬럼값은 MySQL 이 해당 테이블의 검색에 사용할수 있는 인덱스들을 나타낸다.
주의할것은 explain 결과에서 나타난 테이블들의 순서와는 무관하다는 것이다.
이것은 possible_keys 에 나타난 인덱스들이 결과에 나타난 테이블 순서에서 실제 사용할 수 없을수도 있다는 것을 의미한다.
이값이 NULL 이라면 사용가능한 인덱스가 없다는 것이다. 이러한 경우에는 인덱스를 where 절을 고려하여 사용됨직한 적절한 컬럼에 인덱스를 추가함으로써 성능을 개선할 수 있다. 인덱스를 수정하였다면 다시한번 EXPLAIN 을 실행하여 체크하라.
See Section 13.2.2, “ALTER TABLESyntax”.현재 테이블의 인덱스를 보기 위해서는
SHOW INDEX FROM.을 사용하라.tbl_namekey이 컬럼은 MySQL 이 실제 사용한 key(index) 를 나타낸다.
만약 사용한 인덱스가 없다면 NULL 값일 것이다. MySQL 이 possible_keys 에 나타난 인덱스를 사용하거나 사용하지 않도록 강제하려면 FORCE INDEX,USE INDEX, 혹은IGNORE INDEX를 함께 사용하라.
See Section 13.1.7, “SELECTSyntax”.MyISAM 과
BDB테이블에서는 ANALYZE TABLE 이 옵티마이저가 더나은 인덱스를 선택할 수 있도록 테이블의 정보를 갱신한다.
MyISAM 에서는 myisamchk --analyze 가 같은 기능을 한다.
See Section 13.5.2.1, “ANALYZE TABLESyntax” and Section 5.7.2, “Table Maintenance and Crash Recovery”.key_len이 컬럼은 MySQL 이 사용한 인덱스의 길이를 나타낸다. key 컬럼값이 NULL 이면 이값도 NULL 이다.
key_len 값으로 MySQL 이 실제 복수컬럼 키중 얼마나 많은 부분을 사용할 것인지 알 수 있다.
ref이 컬럼은 행을 추출하는데 키와 함께 사용된 컬럼이나 상수값을 나타낸다.
rows이 값은 쿼리 수행에서 MySQL 이 예상하는 검색해야할 행수를 나타낸다.
Extra이 컬럼은 MySQL 이 쿼리를 해석한 추가적인 정보를 나타낸다.
아래와 같은 값들이 나타날 수 있다.
DistinctMySQL 이 매치되는 첫행을 찾는 즉시 검색을 중단할 것이다.
Not existsMySQL 이 LEFT JOIN 을 수행함에 매치되는 한 행을 찾으면 더이상 매치되는 행을 검색하지 않는다.
아래와 같은 경우에 해당한다.SELECT * FROM t1 LEFT JOIN t2 ON t1.id=t2.id WHERE t2.id IS NULL;
여기서 t2.id 는 NOT NULL 이고, 이경우 MySQL 은 t1 을 스캔한 후 t1.id 값을 사용해 t2 를 검색한다. MySQL 이 t2 에서 매치되는 행을 찾으면 t2.id 는 NULL 이 될 수 없으므로 더이상 진행하지 않는다. 즉, t1 의 각 행에 대해 t2 에서 매치되는 행이 몇개가 있던지 한개만 찾으면 된다.
range checked for each record (index map: #)MySQL 이 사용할 좋은 인덱스가 없다. 그러나 선행된 테이블의 컬럼값에 따라 몇몇 인덱스를 사용할 수 있다. 선행된 테이블의 개개 행에 대해 MySQL 이 range 나 index_merge 접근법을 사용할 수 있는지 체크할 것이다.
적용가능성의 핵심은 Section 7.2.5, “Range Optimization” and Section 7.2.6, “Index Merge Optimization” 에 모든 선행된 테이블의 값이 명확하거나 상수인 때를 예외로 하여 기술되어 있다.
이것은 그리 빠르진 않으나 인덱스가 없는 조인의 경우보다는 빠르다.Using filesortMySQL 이 정렬을 위해 추가적인 과정을 필요로한다. 정렬과정은 조인타입에 따라 모든 행을 검색하고 WHERE 절에 의해 매치된 모든 행들의 키값을 저장한다. 그리고 저장된 키값을 정렬하여 재정렬된 순서로 행들을 추출한다.
See Section 7.2.10, “How MySQL OptimizesORDER BY”.
Using index컬럼정보가 실제 테이블이 아닌 인덱스트리에서 추출된다. 쿼리에서 단일 인덱스된 컬럼들만을 사용하는 경우이다.
Using temporaryMySQL 이 결과의 재사용을 위해 임시테이블을 사용한다. 쿼리 내에 GROUP BY 와 ORDER BY 절이 각기 다른 컬럼을 사용할때 발생한다.
Using whereWHERE 절이 다음 조인에 사용될 행이나 클라이언트에게 돌려질 행을 제한하는 경우이다. 테이블의 모든 행을 검사할 의도가 아니라면 Extra 값이 Using where 가 아니고 조인타입이 ALL 이나 index 라면 쿼리사용이 잘못되었다.
쿼리를 가능한 한 빠르게 하려면, Extra 값의 Using filesort 나 Using temporary 에 주의해야 한다.
Using sort_union(...) ,Using union(...),Using intersect(...)
이들은 인덱스 병합 조인타입에서 인덱스 스캔이 병합되는 형태를 말한다.
See Section 7.2.6, “Index Merge Optimization” for more information.
Using index for group-by테이블 접근방식은 Using index 와 같다. MySQL 이 실제 테이블에 대한 어떠한 추가적인 디스크 접근 없이 GROUP BY 나 DICTINCT 쿼리에 사용된 모든 컬럼에 대한 인덱스를 찾았음을 말한다. 추가적으로 각각의 group 에 단지 몇개의 인덱스 항목만이 읽혀지도록 가장 효율적인 방식으로 인덱스가 사용될 것이다.
For details, see Section 7.2.11, “How MySQL OptimizesGROUP BY”.
EXPLAIN 의 출력내용중 rows 컬럼값들을 곱해봄으로써 얼마나 효과적인 join 을 실행하고 있는지 알 수 있다. 이 값은 MySQL 이 쿼리수행중 검사해야할 행수를 대략적으로 알려준다. 만약 max_join_size 시스템 변수값을 설정하였다면 이 값은 또한 여러테이블을 사용하는 select 중 어느것을 먼저 실행할지 판단하는데 사용된다.
See Section 7.5.2, “Tuning Server Parameters”.
다음 예는 다중테이블 조인이 EXPLAIN 정보를 통해 점차적으로 개선되는 과정을 보여준다. 만약 아래와 같은 select 문을 EXPLAIN 으로 개선한다면 :
EXPLAIN SELECT tt.TicketNumber, tt.TimeIn,
tt.ProjectReference, tt.EstimatedShipDate,
tt.ActualShipDate, tt.ClientID,
tt.ServiceCodes, tt.RepetitiveID,
tt.CurrentProcess, tt.CurrentDPPerson,
tt.RecordVolume, tt.DPPrinted, et.COUNTRY,
et_1.COUNTRY, do.CUSTNAME
FROM tt, et, et AS et_1, do
WHERE tt.SubmitTime IS NULL
AND tt.ActualPC = et.EMPLOYID
AND tt.AssignedPC = et_1.EMPLOYID
AND tt.ClientID = do.CUSTNMBR;
이 예에서 아래와 같은 가정이 사용되었다.:
The columns being compared have been declared as follows:
Table Column Column Type ttActualPCCHAR(10)ttAssignedPCCHAR(10)ttClientIDCHAR(10)etEMPLOYIDCHAR(15)doCUSTNMBRCHAR(15)The tables have the following indexes:
Table Index ttActualPCttAssignedPCttClientIDetEMPLOYID(primary key)doCUSTNMBR(primary key)The
tt.ActualPCvalues are not evenly distributed.
먼저, 개선되기 전의 EXPLAIN 은 다음과 같은 정보를 보여준다.:
table type possible_keys key key_len ref rows Extra
et ALL PRIMARY NULL NULL NULL 74
do ALL PRIMARY NULL NULL NULL 2135
et_1 ALL PRIMARY NULL NULL NULL 74
tt ALL AssignedPC, NULL NULL NULL 3872
ClientID,
ActualPC
range checked for each record (key map: 35)
각 테이블의 type 이 ALL 을 나타내므로, MySQL 이 모든 테이블의 카티션곱(Cartesian product) 를 생성한다는 것을 나타낸다.
각 테이블의 행의 조합이 모두 검사되어야 하기 때문에 이것은 아주 오랜 시간이 소요될 것이다.
실제로 이 결과는 74 * 2135 * 74 * 3872 = 45,268,558,720 행에 달한다.
만약 테이블이 더 크다면 얼마나 소요될지 상상할 수도 없을 것이다.
여기서 우선적인 문제는 MySQL 은 같은 타입으로 선언된 컬럼의 인덱스를 더 효과적으로 사용할 수 있다는 것이다. (ISAM 테이블에서는 같은 타입으로 선언되지 않은 인덱스는 사용할 수 없다.) 여기에서 VARCHAR 과 CHAR 은 길이가 다르지 않다면 같은 타입이다.
tt.ActualPC 는 CHAR(10) 이고 et.EMPLOYID 는 CHAR(15) 로 선언되어 있으므로 길이의 불일치가 발생한다.
이러한 컬럼 길이의 불일치 문제의 해결을 위해 ALTER TABLE 을 사용하여 ActualPC 컬럼을 10 글자에서 15 글자로 변경하자 (길이를 늘리는것은 데이타 손실이 없다.)
mysql> ALTER TABLE tt MODIFY ActualPC VARCHAR(15);
이제 tt.ActualPC 와 et.EMPLYID 는 모두 VARCHAR(15) 이다. 다시 EXPLAIN 을 실행해보면 다음 결과와 같다.
table type possible_keys key key_len ref rows Extra
tt ALL AssignedPC, NULL NULL NULL 3872 Using
ClientID, where
ActualPC
do ALL PRIMARY NULL NULL NULL 2135
range checked for each record (key map: 1)
et_1 ALL PRIMARY NULL NULL NULL 74
range checked for each record (key map: 1)
et eq_ref PRIMARY PRIMARY 15 tt.ActualPC 1
훨씬 좋아졌지만 아직 완벽하지 않다. 행의 곱은 이제 74 만큼 줄었다.
이 쿼리는 이제 몇초만에 실행될 것이다.
두번째 작업은 tt.AssignedPC = et_1.EMPLYID 와 tt.ClientID = do.CUSTNMBR 에서의 컬럼길이의 불일치를 수정하는 것이다.
mysql> ALTER TABLE tt MODIFY AssignedPC VARCHAR(15),
-> MODIFY ClientID VARCHAR(15);
이제 EXPLAIN 은 다음과 같은 결과를 보여준다.
table type possible_keys key key_len ref rows Extra
et ALL PRIMARY NULL NULL NULL 74
tt ref AssignedPC, ActualPC 15 et.EMPLOYID 52 Using
ClientID, where
ActualPC
et_1 eq_ref PRIMARY PRIMARY 15 tt.AssignedPC 1
do eq_ref PRIMARY PRIMARY 15 tt.ClientID 1
이것은 이제 거의 최적의 결과가 된 것 같다.
남아있는 문제는 MySQL 이 기본으로 tt.ActualPC 컬럼의 값이 균등하게 분포되어 있다고 가정한다는 것이다. 하지만 tt 테이블은 실제로 그렇지 않다.
다행히도 MySQL 이 키 분포를 검사하도록 하는것은 매우 쉽다.
mysql> ANALYZE TABLE tt;
이제 완벽한 조인이 되었다. EXPLAIN 결과는 다음과 같다.
table type possible_keys key key_len ref rows Extra
tt ALL AssignedPC NULL NULL NULL 3872 Using
ClientID, where
ActualPC
et eq_ref PRIMARY PRIMARY 15 tt.ActualPC 1
et_1 eq_ref PRIMARY PRIMARY 15 tt.AssignedPC 1
do eq_ref PRIMARY PRIMARY 15 tt.ClientID 1
EXPLAIN 결과의 rows 컬럼값이 나타내는 MySQL 최적화에 의해 예측된 행수에 주목하라.
나타난 숫자가 실제 행수에 근접한지 체크해야 한다. 그렇지 않다면 STRAIGHT_JOIN 를 사용고 FROM 절에서 테이블의 순서를 변경함으로써 더 나은 성능을 얻을 수 있다.
작게 생각하기
- 조만간 규모가 커질거라면 MySQL ecosystem을 봐야된다.
- 그리고 캐싱 빡시게 안 하는 메이저 웹사이트는 없다.
- develooper.com의 Hansen PT랑 Ilia 튜토리얼 볼 것
- 처음부터 확장 가능하게 아키텍처 잘 쪼개놔야된다.
- 복제랑 파티셔닝 어떻게 할지 미리 계획 세워놔라.
- 파일 기반 세션 좀 쓰지마 -_-
- 그렇다고 너무 쓸데없이 크게 생각하지도 말 것
- 특히 성능하고 확장성 구분 못 하면 난감함
EXPLAIN 안 써보기
- SELECT 앞에 EXPLAIN 이라고 붙이기만 하면 되는 것을 (..)
- 실행 계획 확인
- 타입 컬럼에 index 써있는거랑 Extra 컬럼에 index 써있는거랑 "매우 큰" 차이 있음
* 타입에 있으면 Full 인덱스 스캔 (안 좋다.)
* Extra 컬럼에 있으면 Covering 인덱스 찾았다는 의미임 (좋다!)
- 5.0 이후부터는 index_merge 최적화도 한다.
잘못된 데이터 타입 선택
- 한 메모리 블럭 단위에 인덱스 레코드가 많이 들어갈수록 쿼리가 빨리 실행될 것이다. (중요)
- 아.. 정규화 좀 해 -_-... (이거 정말 충격과 공포인 듯)
- 가장 작은 데이터 타입을 써.. (진짜 BIGINT가 필요하냐고..)
- 인덱스 걸리는 필드는 정말 최소한으로 데이터 크기를 써야된다고.
- IP는 INT UNSIGNED로 저장해!! (아주 공감)
* 이럴 때 쓰라고 INET_ATON 함수가 아예 내장되어 있음.
PHP에서 pconnect 쓰는 짓
- 아파치에서 좀비 프로세스라도 생기면 그 커넥션은 그냥 증발하는거야..
- 어차피 MySQL 접속 속도는 Oracle이나 PostgreSQL 보다 10~100배 빠르다고.
너무 과도한 DB 추상화 계층을 두는 것
- 어디 포팅 열심히 할 거 아니면 추상화 계층 쓰지마 (ADODB, MDB2, PearDB 등)
- scale out 가능한걸 쓰라고.
스토리지 엔진 이해 못 하는 것
- 단일 엔진만으로 전체 아키텍처를 결정했다면 대부분 최적이 아님
- 엔진 별 장단점을 공부할 것
- ARCHIVE : zlib으로 압축해주고 UPDATE 안 되고 로그 Bulk Insert에 유용함.
- MEMORY : 서버 재시작하면 증발. 인덱스가 HASH나 BTREE로 가능함. 임시, 요약 데이터에 사용.
* 주간 top X 테이블 같은 것.
* 하여튼 메모리에 박아넣고 싶은 데이터 있으면..
인덱스 레이아웃 이해 못 하는 것
- 제대로 인덱스랑 스토리지 엔진 선택하려면 공부 좀 해
- 엔진은 데이터와 인덱스 레코드를 메모리나 디스크에 레이아웃하는 걸 구현한 것
- clustered 구성은 데이터를 PK 순서에 따라 저장함.
- non-clustered 구성은 인덱스만 순서대로 저장하고 데이터는 순서 가정하지 않음.
- clustered에서는 인덱스만 타면 추가적인 조회 없이 바로 데이터 가져오는 것임.
- 그래서 clustered PK는 작은 놈으로 할 필요가 있다는거
* 다른 인덱스는 각 레코드마다 PK를 앞에 더 붙이게 되니까.
* PK 지정 안 하면 아무렇게나 해버림
쿼리 캐시 이해 못 하는 것
- 어플리케이션 read/write 비율은 알고 있어야지
- 쿼리 캐시 설계는 CPU 사용과 읽기 성능 간의 타협
- 쿼리 캐시 크기를 늘린다고 읽기 성능이 좋아지는게 아님. heavy read라도 마찬가지.
- 과도한 CPU 사용을 막기 위해 무효화 할 때는 캐시 항목들을 뭉텅이로 날려버림
- 한마디로 SELECT가 참조하는 테이블 데이터 하나라도 변경되면 그 테이블 캐시는 다 날라간다는 얘기임
- 수직 테이블 파티셔닝으로 처방
* Product와 ProductCount를 쪼갠다든지..
* 자주 변하는 것과 변하지 않는 것을 쪼개는게 중요하다 이 말임.
Stored Procedure를 쓰는 것
- 무조건 쓰면 안 된다는게 아니고..
- 컴파일 할 때 무슨 일이 일어나는지 이해 못 하고 쓰면 재앙이 된다 이 말.
- 다른 RDBMS랑 다르게 connection thread에서 실행 계획이 세워짐.
- 이게 뭔 얘기냐 하면 데이터 한 번 가져오고 연결 끊으면 그냥 CPU 낭비 (7~8% 정도)하는 꼴이라는 것.
- 웬만하면 Prepared 구문과 Dynamic SQL을 써라.. 아래 경우를 제외하고
* ETL 타입 프로시저
* 아주아주 복잡하지만 자주 실행되지는 않는 것
* 한 번 요청할 때마다 여러번 실행되는 간단한 것 (연결한 상태로 여러번 써야 된다니까)
인덱스 컬럼에 함수 쓰는 것
- 함수에 인덱스 컬럼 넣어 호출하면 당연히 인덱스 못 탄다
- 함수를 먼저 계산해서 상수로 만든 다음에 = 로 연결해야 인덱스 탈 수 있다.
* 여기 실행 계획 보면 LIKE도 range type 인덱스 타는 것 보임
인덱스 빼먹거나 쓸모없는 인덱스 만들어 놓는 것
- 인덱스 분포도(selectivity)가 허접하면 안 쓴다.
- S = d/n
* d = 서로 다른 값의 수 (# of distinct values)
* n = 테이블의 전체 레코드 수
- 쓸모없는 인덱스는 INSERT/UPDATE/DELETE를 느리게 할 뿐..
- FK는 무조건 인덱스 걸어라. (물론 FK 제약 걸면 인덱스 자동으로 생긴다.)
- WHERE나 GROUP BY 표현식에서 쓰이는 컬럼은 인덱스 추가를 고려할 것
- covering index 사용을 고려할 것
- 인덱스 컬럼 순서에 유의할 것!
join 안 쓰는 짓
- 서브쿼리는 join으로 재작성해라
- 커서 제거해라
- 좋은 Mysql 성능을 내려면 기본
- 집합 기반으로 생각해야지 루프 돌리는거 생각하면 안 된다.
Deep Scan 고려하지 않는 것
- 검색엔진 크러울러가 쓸고 지나갈 수 있다.
- 이 경우 계속해서 전체 집합을 정렬한 다음 LIMIT로 가져와야 하니 무진장 느려진다.
- 어떻게든 집합을 작게 줄인 다음 거기서 LIMIT 걸어 가져올 것
InnoDB 테이블에서 WHERE 조건절 없이 SELECT COUNT(*) 하는 짓
- InnoDB 테이블에서는 조건절 없이 COUNT(*) 하는게 느리다.
- 각 레코드의 transaction isolation을 유지하는 MVCC 구현이 복잡해서 그렇다는..
- 트리거 걸어서 메모리 스토리지 엔진 쓰는 테이블에 통계를 별도로 유지하면 된다.
프로파일링이나 벤치마킹 안 하는 것
- 프로파일링 : 병목 찾아내기
- 벤치마킹 : 시간에 따른 성능 변화 추이 평가, 부하 견딜 수 있는지 테스트
- 프로파일링 할 때는 실제 데이터를 옮겨와서 할 것
- 어디가 병목이냐~ Memory? Disk I/O? CPU? Network I/O? OS?
- 느린 쿼리 로그로 남기기
* log_slow_queries=/path/to/log
* log_queries_not_using_indexes
- 벤치마킹 시에는 다 고정시키고 변수 하나만 바꿔가면서 해야 함. (쿼리 캐시는 끌 것.)
- 도구를 써라~~
* EXPLAIN
* SHOW PROFILE
* MyTop/innotop
* mysqlslap
* MyBench
* ApacheBench (ab)
* super-smack
* SysBench
* JMeter/Ant
* Slow Query Log
AUTO_INCREMENT 안 쓰는 것
- PK를 AUTO_INCREMENT로 쓰는건 무진장 최적화 되어 있음
* 고속 병행 INSERT 가능
* 잠금 안 걸리고 읽으면서 계속 할 수 있다는!
- 새 레코드를 근처에 놓음으로써 디스크와 페이지 단편화를 줄임
- 메모리와 디스크에 핫 스팟을 생성하고 스와핑을 줄임
ON DUPLICATE KEY UPDATE를 안 쓰는 것
- 레코드가 있으면 업데이트하고 없으면 인서트하고 이런 코드 필요없다!! 다 날려버려라!!
- 서버에 불필요하게 왔다갔다 할 필요가 없어짐
- 5-6% 정도 빠름
- 데이터 입력이 많다면 더 커질 수 있음
하지 말아야 할 것 총정리
- Thinking too small
- Not using EXPLAIN
- Choosing the wrong data types
- Using persistent connections in PHP
- Using a heavy DB abstraction layer
- Not understanding storage engines
- Not understanding index layouts
- Not understanding how the query cache works
- Using stored procedures improperly
- Operating on an indexed column with a function
- Having missing or useless indexes
- Not being a join-fu master
- Not accounting for deep scans
- Doing SELECT COUNT(*) without WHERE on an InnoDB table
- Not profiling or benchmarking
- Not using AUTO_INCREMENT
- Not using ON DUPLICATE KEY UPDATEK
 Prev
Prev
