'개발/DB_MYSQL'에 해당되는 글 15건
- 2013.02.25 MySQL 백업 및 복구
- 2011.12.09 mysql procedure 8
- 2009.12.01 Insert text file into MySQL 1
- 2009.06.25 [MySQL] Replication 환경 싱크 깨지는것 회피하기
- 2009.06.11 mysql show status
- 2009.06.01 [mysql] Index Hint Syntax 1
- 2009.06.01 [MYSQL] Alter table 명령어
- 2009.03.18 17.4. 스토어드 루틴 및 트리거의 바이너리 로깅
- 2009.03.13 Dual-Master Replication in MySQL
- 2009.03.02 Windows에서 MySQL 설치하기
MySQL 백업 및 복구
- MySQL 디렉토리 전체를 압축 백업하기
mysql dir : /var/lib (데이터베이스 디렉토리)
[root@byungun lib]# tar cvfpz mysql_dir_tar.gz /var/lib/mysql
- 특정 데이터베이스 백업과 복구
백업 형식 : mysqldump -u DB계정명 -p DB명 > 저장할파일명
복구 형식 : mysql -u DB계정명 -p DB명 < 저장할파일명
# mysql DB 백업
[root@byungun DB_backup]# mysqldump -u root -p mysql > mysqldb.sql
Enter password:
# mysql DB 생성
[root@byungun DB_backup]# mysqladmin -u root -p create mysql
Enter password:
# mysql DB 복구
[root@byungun DB_backup]# mysql -u root -p mysql < mysqldb.sql
Enter password:
- 특정 데이터베이스의 특정 테이블 백업과 복구
백업 형식 : mysqldump -u DB계정명 -p DB명 Table명 > 저장할파일명
복구 형식 : mysql -u DB계정명 -p DB명 < 저장할파일명
# mysql DB Table 백업
[root@byungun DB_backup]# mysqldump -u root -p testdb testtable > testtable_table.sql
Enter password:
# mysql DB Table 복구
[root@byungun DB_backup]# mysql -u root -p testdb < testtable_table.sql
Enter password:
- 여러 개의 데이터베이스 한 번에 백업과 복구
백업 형식 : mysqldump -u DB계정명 -p --databases [옵션] DB1 DB2 DB3 > 저장할파일명
복구 형식 : mysql -u DB계정명 -p < 저장할파일명
# mysql 여러 개의 DB 백업
[root@byungun DB_backup]# mysqldump -u root -p --databases tempdb testdb > various_db.sql
Enter password:
# mysql DB 복구
[root@byungun DB_backup]# mysql -u root -p < various_db.sql
Enter password:
- MySQL 전체 데이터베이스 백업과 복구
백업 형식 : mysqldump -u DB계정명 -p --all-databases > 저장할파일명
복구 형식 : mysql -u DB계정명 -p < 저장할파일명
[root@byungun DB_backup]# mysql -u root -p --all-databases > mysql_alldb.sql
Enter password:
CREATE TABLE my_bundles(seq int auto_increment, total int, bundle text, PRIMARY KEY (seq));
INSERT INTO my_bundles(total,bundle) VALUES (3,"JAVASCRIPT,ACTIONSCRIPT,HTML"),(1,"C++"),(2,"ALGOL,C#"),(7,"C,PHP,JSP,LISP,BASIC,ADA,PYTHON"),(6,"JAVA,RUBY,PASCAL,COBOL,FORTRAN,PERL"),(5,"DELPHI,PROLOG,SMALLTALK,PERL,COLDFUSION");
SELECT * FROM my_bundles;
DROP TABLE IF EXISTS my_items;
CREATE TABLE my_items(seq int auto_increment, language varchar(32), PRIMARY KEY (seq));
DELIMITER $$
DROP PROCEDURE IF EXISTS tokenizer $$
CREATE PROCEDURE tokenizer(
INOUT input_string varchar(1025), OUT token varchar(1025), IN boundary varchar(16)
) READS SQL DATA
BEGIN
SELECT char_length(boundary) INTO @boundry_length;
SET @idx = LOCATE(boundary,input_string);
IF (@idx = 0) THEN
SET token = input_string;
SET input_string = NULL;
ELSE
SET token = SUBSTR(input_string,1,@idx-1);
SET input_string = SUBSTR(input_string,@idx + @boundry_length);
END IF;
END
$$
DELIMITER ;
DELIMITER $$
DROP PROCEDURE IF EXISTS insert_items $$
CREATE PROCEDURE insert_items(IN my_str varchar(1024)) MODIFIES SQL DATA
BEGIN
SELECT my_str INTO @org_string;
CALL tokenizer(@org_string, @tkn_str, ',');
WHILE (@tkn_str IS NOT NULL) DO
INSERT INTO my_items(language) VALUES (@tkn_str);
CALL tokenizer(@org_string, @tkn_str, ',');
END WHILE;
END
$$
DELIMITER ;
CALL insert_items('a,b,c');
SELECT * FROM my_items;
DELIMITER $$
DROP PROCEDURE IF EXISTS insert_cols_items $$
CREATE PROCEDURE insert_cols_items()
BEGIN
DECLARE ok INT DEFAULT '0';
DECLARE tmp_seq INT DEFAULT '0';
DECLARE tmp_total INT DEFAULT '0';
DECLARE tmp_bundle TEXT DEFAULT '';
DECLARE tot INT DEFAULT '0';
DECLARE cur CURSOR FOR SELECT seq, total, bundle FROM my_bundles;
DECLARE CONTINUE HANDLER FOR SQLSTATE '02000' SET ok = 1;
OPEN cur;
REPEAT
FETCH cur INTO tmp_seq, tmp_total, tmp_bundle;
IF NOT ok THEN
CALL insert_items(tmp_bundle);
SET tot = tot + 1;
END IF;
UNTIL ok END REPEAT;
CLOSE cur;
IF tot > 0 THEN
SELECT tot;
ELSE
SELECT 0;
END IF;
END
$$
DELIMITER ;
TRUNCATE my_items;
CALL insert_cols_items();
SELECT * FROM my_items;
import java.io.File;
import java.io.FileInputStream;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
public class InsertTextFileToMySQL {
public static Connection getConnection() throws Exception {
String driver = "org.gjt.mm.mysql.Driver";
String url = "jdbc:mysql://localhost/databaseName";
String username = "root";
String password = "root";
Class.forName(driver);
Connection conn = DriverManager.getConnection(url, username, password);
return conn;
}
public static void main(String[] args)throws Exception {
String id = "001";
String fileName = "fileName.txt";
FileInputStream fis = null;
PreparedStatement pstmt = null;
Connection conn = null;
try {
conn = getConnection();
conn.setAutoCommit(false);
File file = new File(fileName);
fis = new FileInputStream(file);
pstmt = conn.prepareStatement("insert into DataFiles(id, fileName, fileBody) values (?, ?, ?)");
pstmt.setString(1, id);
pstmt.setString(2, fileName);
pstmt.setAsciiStream(3, fis, (int) file.length());
pstmt.executeUpdate();
conn.commit();
} catch (Exception e) {
System.err.println("Error: " + e.getMessage());
e.printStackTrace();
} finally {
pstmt.close();
fis.close();
conn.close();
}
}
}
MySQL의 리플리케이션 환경을 운영하다 보면 유난히도 싱크가 어긋나는 일이 많이 일어나는 것을 알 수 있습니다.
확실히 MySQL은 아직 엔터프라이즈 환경에서의 도입에 무리가 있는 제품이 아닐까 생각이 드는군요.
하지만 리플리케이션 기능이 추가된지 얼마 되지 않았고 저장프로시저도 생겼고 나날이 발전하는 모습을 보면 더더욱 좋아질것이라고 기대해 봅니다.
그러면 이미 MySQL을 이용한 리플리케이션 상황을 운영중이고 또 관련 오류가 많이 나는 상황이라면 어떻게 해야 할까요?
다음의 방법을 시도해볼만합니다.
MySQL의 경우 리플리케이션 환경 중 에러가 나면 그 Slave 서버는 리플리케이션이 중단됩니다.
갑자기 좀비 서버가 되어 버리는 것이죠. 에러를 확인해 봅시다.
[root@SLAVE ~]# mysql
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 2060
Server version: 5.0.51
Type 'help;' or '\h' for help. Type '\c' to clear the buffer.
mysql> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: MASTER
Master_User: replicator
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000005
Read_Master_Log_Pos: 96305365
Relay_Log_File: slave-relay-bin.000006
Relay_Log_Pos: 73184178
Relay_Master_Log_File: mysql-bin.000005
Slave_IO_Running: Yes
Slave_SQL_Running: No
Replicate_Do_DB: THEEYE
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 1062
Last_Error: Error 'Duplicate entry '116069-10002826' for key 1' on query. Default database: 'THEEYE'. Query: 'INSERT INTO THEEYE_INFO_LOG ( IDX, NAME, REG_DATE ) VALUES ( 3, "GOOD", NOW() )'
Skip_Counter: 0
Exec_Master_Log_Pos: 73184876
Relay_Log_Space: 96304951
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: NULL
1 row in set (0.00 sec)
mysql> exit
show slave status\G 명령으로 현재 슬레이브의 상태를 확인할 수 있습니다.
상태를 보니 Last_Errno 가 1062이고 Last_Error에는 어떤 에러인지 표시가 됩니다.
근데 에러를 확인해 보니 같은 똑같은 Entry가 존재한다는군요. 위의 디비 설계상 같은 키값을 가진 값이 두개가 들어갈 필요가 없다는것을 알았습니다.
그런데 저런 사소한 문제로 리플리케이션이 중단된다는것도 억울한 일이죠. 위와 같은 사소한 에러는 무시하도록 해보겠습니다.
--slave-skip-errors 라는 옵션이 있는데요. 에러코드값을 지정해 주거나 all로 모든 에러를 무시할 수 있습니다.
--slave-skip-errors=[err_code1,err_code2,...|all]서버측 에러 코드는 [ 이곳 ] 에서 확인 하실 수 있습니다.
1062번 에러의 경우 사소한 문제이기 때문에 서버 설정에 추가해 보도록 하겠습니다.
저같은 경우에는 /etc/my.cnf 파일에 다음의 내용을 추가하였습니다.
[mysqld]
...
slave-skip-errors = 1062앞으로는 위의 코드에 해당하는 에러가 발생할 경우 에러를 건너뛰고 Master의 Log Position에 강제적으로 맞춰질 것입니다.
설명:
Aborted_clients : 클라이언트가 연결을 적절히 닫지않아서 죽었기때문에 끊어진 연결수.
Aborted_connects : 연결실패된 mysql서버에 연결시도 수.
Bytes_received : 모든 클라이언트로 부터 받은 바이트 수
Bytes_sent : 모든 클라이언트에게 보낸 바이트수
Connections : mysql서버에 연결시도한 수
Created_tmp_disk_tables : sql문을 실행하는 동안 생성된 디스크에 존재하는 임시테이블 수
Created_tmp_tables : sql문을 실행하는 동안 생성된 메모리에 존재하는 임시테이블 수
Created_tmp_files : 얼마나 많은 임시파일을 mysqld가 생성했는가
Delayed_insert_threads : 사용중인 insert handler threads가 지연되고 있는 수
Delayed_writes : INSERT DELAYED로 쓰여진 rows수
Delayed_errors : 어떤 에러(duplicate key로인한 때문에 INSERT DELAYED로 쓰여진 rows수
Flush_commands : 초과 flush명령수
Handler_delete : 테이블로 부터 지워진 rows수
Handler_read_first : 인덱스로 부터 읽혀진 처음 entry수. 이것이 높으면 서버는 많은 full
index scans를 하고 있다는 것을 의미. 예를 들어 SELECT col1 FROM
foo는 col1은 인덱스되었다는 것을 추정.
Handler_read_key : 키가 존재하는 row를 읽는 요청수. 이것이 높으면 당신의 쿼리와 테이블
이 적절히 인덱스화되었다는 좋은 지적이 된다.
Handler_read_next : 키순서대로 다음 row를 읽는 요청수. 이것은 만약 range constraint와
함께 인덱스컬럼을 쿼리할 경우 높아질 것이다. 이것은 또한 인덱스 스캔
하면 높아질 것이다.
Handler_read_rnd : 고정된 위치에 존재하는 row를 읽는 요청수. 이것은 결과를 정렬하기를
요하는 많은 쿼리를 한다면 높아질 것이다.
Handler_read_rnd_next : 데이타파일에서 다음 row를 읽기를 요청수. 이것은 많은 테이블 스
캔을 하면 높아질 것이다.
Handler_update : Number of requests to update a row in a table.
한테이블에 한 row를 업데이트를 요청하는 수
Handler_write : 한테이블에 한 row를 insert요청하는 수
Key_blocks_used : key 캐시에서 블럭을 사용하는 수
Key_read_requests : 캐시에서 키블럭을 읽기를 요청하는 수
Key_reads : 디스크로부터 키블럭을 물리적으로 읽는 수
Key_write_requests : 캐시에서 키블럭을 쓰기위해 요청하는 수
Key_writes : 디스크에 키블럭을 물리적으로 쓰는 수
Max_used_connections : 동시사용 연결 최대수
Not_flushed_key_blocks : 키캐시에서 키블럭이 바뀌지만 디스크에는 아직 flush되지 않는다.
Not_flushed_delayed_rows : INSERT DELAY queue에서 쓰여지기를 기다리는 row수
Open_tables : 현재 오픈된 테이블수
Open_files : 현재 오픈된 파일수
Open_streams : 주로 logging에 사용되는 현재 오픈된 stream수
Opened_tables : 지금까지 오픈된 테이블 수
Select_full_join : 키없이 조인된 수(0이 되어야만 한다)
Select_full_range_join : reference table에서 range search를 사용한 조인수
Select_range : 첫번째 테이블에 range를 사용했던 조인수. 보통 이것이 크더라도 위험하진 않다.
Select_scan : 첫번째 테이블을 스캔했던 조인수
Select_range_check : 각 row후에 key usage를 체크한 키없이 조인한 수(0이어야만 한다)
Questions : 서버에서 보낸 쿼리수
Slave_open_temp_tables : 현재 slave thread에 의해 오픈된 임시 테이블 수
Slow_launch_threads : 연결된 slow_launch_time보다 더 많은 수를 갖는 쓰레드수
Slow_queries : long_query_time보다 더 많은 시간이 걸리는 쿼리 수. Slow Query Log참고
Sort_merge_passes : 정렬해야만 하는 merge수.
이 값이 크면 sort_buffer를 증가하는것에 대해 고려해야 한다.
Sort_range : Number of sorts that where done with ranges.
Sort_rows : 정렬된 row수
Sort_scan : 테이블 스캔에 의해 행해진 정렬수
Table_locks_immediate : 즉시 획득된 테이블 lock 시간 (3.23.33부터 추가된 항목)
Table_locks_waited : 즉시 획득되지 않고 기다림이 필요한 테이블 lock 시간. 이것이 높아지면 성능에 문제가 있으므로, 먼저 쿼리를 최적화 시키고, 테이블을 분산시키거나 복제를 사용해야 한다. (3.23.33부터 추가된 항목)
Threads_cached : 스레드 캐시에서 쓰레드 수
Threads_connected : 현재 오픈된 연결수
Threads_created : 연결을 다루기위해 생성된 쓰레드 수
Threads_running : sleeping하지 않는 쓰레드 수
Uptime : 서버가 스타트된 후로 지금까지의 시간
You can provide hints to give the optimizer information about how to choose indexes during query processing. Section 12.2.7.1, “JOIN Syntax”, describes the general syntax for specifying tables in a SELECT statement. The syntax for an individual table, including that for index hints, looks like this:
By specifying USE INDEX (index_list), you can tell MySQL to use only one of the named indexes to find rows in the table. The alternative syntax IGNORE INDEX (index_list) can be used to tell MySQL to not use some particular index or indexes. These hints are useful if EXPLAIN shows that MySQL is using the wrong index from the list of possible indexes.
You can also use FORCE INDEX, which acts like USE INDEX (index_list) but with the addition that a table scan is assumed to be very expensive. In other words, a table scan is used only if there is no way to use one of the given indexes to find rows in the table.
USE KEY, IGNORE KEY, and FORCE KEY are synonyms for USE INDEX, IGNORE INDEX, and FORCE INDEX.
Each hint requires the names of indexes, not the names of columns. The name of a PRIMARY KEY is PRIMARY. To see the index names for a table, use SHOW INDEX.
Index hints do not work for FULLTEXT indexes.
USE INDEX, IGNORE INDEX, and FORCE INDEX affect only which indexes are used when MySQL decides how to find rows in the table and how to do the join. They do not affect whether an index is used when resolving an ORDER BY or GROUP BY clause. As of MySQL 5.0.40, the optional FOR JOIN clause can be added to make this explicit.
Examples:
1. 테이블에 새로운 컬럼 추가
alter table tablename add column [추가할 컬럼명] [추가할 컬럼 데이타형]
2. 테이블에 컬럼타입 변경하기
alter table tablename modify column [변경할 컬럼명] [변경할 컬럼 타입]
3. 테이블에 컬럼이름 변경하기
alter table tablename change column [기존 컬럼명] [변경할 컬럼명] [변경할 컬럼타입]
4. 테이블에 컬럼 삭제하기
alter table tablename drop column [삭제할 컬럼명]
5. 테이블컬럼에 인덱스 주기
alter table tablename add index 인덱스명(인덱스를 줄 컬럼1 , 인덱스를 줄 컬럼2, ... )
6. 테이블컬럼에 인덱스 삭제하기
alter table tablename drop index 인덱스명;
7. 테이블에 Primary Key 만들기
alter table tablename add primary key (키를 줄 컬럼명1 , 키를 줄 컬럼명2, ...)
8. 테이블에 Primary Key 삭제하기
alter table tablename drop primary key;
9. 테이블명 바꾸기
alter table 기존테이블명 rename 새로운테이블명
10. 인덱스 생성
CREATE [UNIQUE] INDEX index_name ON tbl_name (col_name[(length]),... )
11. 인덱스 삭제
DROP INDEX index_name
리 플리케이션의 경우, 마스터 서버는 자신의 바이너리 로그에 포함된 이벤트를 자신의 슬레이브에 전달하는데, 이렇게 함으로서 서버에서 이루어진 데이터의 변경과 동일한 내용을 전달된 이벤트가 실행하도록 하게 한다 . Section 6.2, “리플리케이션 구현 소개” 참조.
특정 데이터 복구 동작은 바이너리 로그의 사용을 요구한다. 백업 파일이 재저장된 후에, 백업이 이루어진 후 기록된 바이너리 로그에 있는 이벤트가 재 실행된다. 이러한 이벤트들은 백업이 이루어지는 시점부터 데이터 베이스를 갱신하게 낸다. Section 5.10.2.2, “복구를 위한 백업 사용하기” 참조.
이 섹션에서는 MySQL 5.0에 있는 스토어드 루틴(프로시저 및 함수)와 트리거에 관련된 바이너리 로깅의 개발을 설명하도록 하겠다. 첫 번째로는 로깅 실행에서 발생하는 변경 사항에 대해 정리를 할 것이고, 그 다음에는 스토어드 루틴의 사용에서 있게 되는 실행의 현재 조건문(current condition)에 대해 언급하기로 한다. 마지막으로, 언제 그리고 어떻게 다앵한 변경이 만들어 지는지에 대한 정보를 제공하는 실행에 대한 자세한 내용을 설명하겠다. 이러한 상세 내용들은 현재의 로깅 행위에 관련된 몇몇 사항이 이전 버전과는 어떻게 달리 실행되는지를 보여 준다.
일반적으로, 여기에서 설명하는 논제들은 바이너리 로깅이 SQL명령문 레벨에서 생긴다는 사실에서부터 출발한다. 향후의 MySQL버전은 로우-레벨(row-level) 바이너리 로깅을 실행할 예정이며, SQL명령문의 실행으로 인해 각 개별 열(row)을 변경시키는 것을 열거할 것이다.
다른 것들은 고려하지 말고, --log-bin옵션으로 서버를 구동해서 바이너리 로깅을 활성화 시켰다고 가정하자. ( Section 5.12.3, “The Binary Log” 참조.) 만일 바이너리 로그가 활성화 되지 않는다면, 리플리케이션은 불가능하게 되거나, 또는 데이터 복구를 위한 바이너리 로그가 불가능하게 된다.
MySQL 5.0 에서 스토어드 루틴 로깅의 개발은 아래와 같이 요약할 수 있다 :
MySQL 5.0.6 이전 버전 : 스토어드 루틴 로깅의 초기 실행에서, 스토어드 루틴과 CALL 명령문을 생성하는 명령문은 로그 되지 않음. 이러한 누락은 리플리케이션과 데이터 복구에 문제를 야기할 수 있다.
MySQL 5.0.6 : 스토어드 루틴과 CALL 명령문을 생성하는 명령문은 로그 되어짐. 스토어드 함수 호출은 데이터를 업데이트 하도록 하는 명령문이 실행될 때 로그 되어 진다 (이러한 명령문들이 로그 되어졌기 때문에). 하지만, 비록 함수 자체에서 데이터의 변경이 이루어 진다 하더라도, 데이터를 변경시키지 않는 SELECT와 같은 명령문이 실행될 때에는 로그 되어지지 않는다; 이것은 문제를 일으키게 된다. 어떤 환경에서는, 서로 다른 시간 또는 서로 다른(서버 및 슬레이브)기계에서 함수 및 프로시저가 실행된다면 서로 다른 영향을 받을 수 있기 때문에 데이터 복구 또는 리플리케이션 자체가 불안정할 수 있다. 이런 문제를 처리하기 위해, 안정적인 루틴의 동일성을 제공하고, 충분한 권한을 갖고 있는 사용자에 의한 행위를 제외한, 일반적으로 불안정한 루틴을 방지하기 위한 조치가 실행된다.
MySQL 5.0.12: 스토어드 함수에 대해서는, 데이터를 변경시키는 함수 호출이 SELECT와 같이 로그 되지 않는(non-logged)명령어 내에서 발생할 때, 서버는 그 함수를 호출하는 DO 명령문을 로그 시킴으로써 데이터가 복구되거나 슬레이브 서버에 리플리케이션되는 동안 함수가 실행되도록 한다. 스토어드 프로시저에 대해서는, 서버는 CALL 명령문을 로그 시키지 못한다. 대신에, 서버는 CALL명령문의 결과로 실행되는 프로시저에 포함되어 있는 개별 명령문은 로그 시킨다. 이것은 프로시저가 마스터 서버가 아닌 슬레이브 서버상에서 서로 다른 실행 경로를 따라 실행될 때 발생할 수 있는 문제들을 제거한다.
MySQL 5.0.16: MySQL 5.0.12에서 제공하는 프로시저 로깅 변경을 통해 불안정한 루틴상의 조건문이 스토어드 프로시저에 대해 안정적으로 동작하도록 해 준다. 따라서, 이러한 조건문을 제어하는 사용자 인터페이스를 함수에 적용 되도록 수정한다. 프로시저 생성자를 더 이상 제한 할 수 없게 되는 것이다.
앞에서 설명한 변경의 결과로, 바이너리 로깅이 활성화될 때에 다음에서 설명하는 조건문을 스토어드 함수에 적용할 수 있게 된다. 이러한 조건문은 스토어드 프로시저 생성에는 적용되지 않는다.
스토어드 함수를 생성 또는 변경하기 위해서는, 일반적으로 CREATE ROUTINE 또는 ALTER ROUTINE 권한을 요구하는 것에 더불어. 반드시 SUPER 권한을 가져야 한다.
스 토어드 함수를 생성할 때에는, 그것이 확정적(deterministic)인지 또는 그것이 데이터를 수정하는 않는다는 것을 선언해야 한다. 그렇지 않으면, 그 함수는 데이터 복구 또는 리플리케이션에 대해 덜 안정한 상태가 되어 버린다. 함수의 특성 중에 두 가지가 여기에 적용된다 :
DETERMINISTIC and NOT DETERMINISTIC 특성은 함수가 주어진 입력 값에 대해 항상 동일한 결과를 만드는지 아닌지를 나타낸다. 어떤 특성도 주어지지 않으면, 디폴트는NOT DETERMINISTIC 이며, 따라서 함수를 확정적인 것으로 선언하기 위해서는 DETERMINISTIC를 확실하게 지정해 주어야 한다.
NOW() 함수(또는 동일 기능 함수) 또는 RAND()의 사용은 함수를 반드시 non-deterministic하게 만들어 주는 것은 아니다. NOW()의 경우, 바이너리 로그는 타임스탬프와 복사본은 올바르게 포함한다. 또한, RAND()도 함수내에서 일단 한번 호출 되어 지면 정확하게 복사본을 만들게 된다. (함수 실행 타임스탬프 및 무작위 수는 마스터 서버 및 슬레이브 상에 있는 동일한 암시적 입력(implicit input)으로 간주할 수 있다.)
CONTAINS SQL, NO SQL, READS SQL DATA, 및 MODIFIES SQL DATA 특성은 함수가 데이터를 읽거나 또는 쓰는 정보를 제공한다. NO SQL 또는 READS SQL DATA 는 함수가 데이터를 변경하지 않는다는 것을 나타내는 것이다. 하지만 어떠한 특성도 주어지지 않으면 디폴트가 CONTAIN SQL이 되기 때문에 반드시 이러한 것 중에 하나를 명확히 지정해 주어야 한다.
CREATE FUNCTION 명령문이 디폴트로 수용되도록 하기 위해서는, DETERMINISTIC 또는 NO SQL 및 READS SQL DATA 중에 한 개는 반드시 확실하게 표현되어야 한다. 그렇지 않으면 에러가 발생한다:
ERROR 1418 (HY000): This function has none of DETERMINISTIC, NO SQL,
or READS SQL DATA in its declaration and binary logging is enabled
(you *might* want to use the less safe log_bin_trust_function_creators
variable)
함수의 특성에 대한 평가는 생성자의 “honesty”를 근거로 한다: MySQL은 DETERMINISTIC으로 선언된 함수가 non-deterministic결과를 만드는 명령문을 갖고 있지 않음을 검사하지 않는다.
함 수 생성(SUPER권한이 있어야 하며 함수가 deterministic으로 선언되거나 또는 데이터를 수정하지 않아야 함)에서 앞에서 언급한 조건을 피하기 위해서는, 글로벌 시스템 변수log_bin_trust_function_creators 를 1로 설정 해야 한다. 디폴트로는, 이 변수의 값은 0이지만, 아래와 같이 변경할 수 있다:
· mysql> SET GLOBAL log_bin_trust_function_creators = 1;
또한, 이 변수는 서버를 구동할 때 --log-bin-trust-function-creators 옵션을 사용해서 설정할 수 있다.
만일 바이너리 로깅이 활성화되지 않으면, log_bin_trust_function_creators 는 적용되지 않으며 루틴 생성을 위한 SUPER는 필요 없게 된다.
트 리거는 스토어드 함수와 유사하고, 따라서 앞에서 언급한 주의 사항 역시 트리거에도 적용된다. 트리거에 대한 예외적인 사항은 다음과 같다: CREATE TRIGGER 는 옵셔널(optional) DETERMINISTIC 특성을 갖지 않기 때문에, 트리거는 항상 deterministic으로 간주된다. 하지만, 이러한 가정은 어떤 경우에서는 틀릴 수도 있다. 예를 들면, UUID() 함수는non-deterministic (그리고 복사되지 않음)이다. 이러한 함수를 트리거에 사용할 경우에는 주의하여야 한다.
트리거는 테이블을 업데이트할 수 있으며(MySQL 5.0.10 버전 현재), 따라서 SUPER권한이 없고 log_bin_trust_function_creators 의 값이 0 이라면, CREATE TRIGGER 과 함께 나타나는 스토어드 함수에 대한 에러 메시지와 비슷한 에러가 발생하게 된다.
이 섹션의 나머지에서는 스토어드 루틴 로깅 개발에 대해서 상세하게 설명하기로 한다. 상세 설명 중에 몇 가지는 현재 스토어드 루틴 사용에서 로깅 관련 조건문에 대한 이론적인 기본 지식을 제공하여 준다.
MySQL 5.0.6 이전 버전에서 루틴 로깅: 스토어드 루틴을 생성하고 사용하는 명령문이 바이너리 로그되는 것이 아니라, 스토어드 루틴내에서 선언된 명령문이 로그되어 진다. 아래의 명령문을 작성 하였다고 가정하자:
CREATE PROCEDURE mysp INSERT INTO t VALUES(1);
CALL mysp;
이 예에서 보면, INSERT 명령문만이 바이너리 로그에서 나타난다. CREATE PROCEDURE 와 CALL 명령문은 나타나지 않는다. 바이너리 로그에서 루틴 관련(routine-related) 명령문이 없다는 것은 스토어드 루틴이 올바르게 복사되지 않았다는 것을 의미한다. 이것은 또한 데이터 복구 동작에 대해, 바이너리 로그에 있는 이벤트의 재실행은 스토어드 루틴를 복구시키지 않는다는 것을 의미하기도 한다.
MySQL 5.0.6에서 루틴 로깅 변경: 스토어드 루틴 생성과 CALL 명령문(그리고 관련된 리플리케이션 및 데이터 복구 문제)에 대한 로깅 부재를 연결(address)하기 위해, 스토어드 루틴에 대한 바이너리 로깅의 특성은 여기에서 설명하였듯이 변경되었다. (아래의 리스트중에 몇 가지 항목은 다음 버전에서 다루어지기 때문에 제외한다.)
서버는CREATE PROCEDURE, CREATE FUNCTION, ALTER PROCEDURE, ALTER FUNCTION, DROP PROCEDURE, 및 DROP FUNCTION 명령문을 바이너리 로그에 쓴다. 또한, 서버는 프로시저내에서 실행되는 명령문이 아닌, CALL 명령문을 로그 한다. 아래의 명령문을 작성하였다고 가정하자:
· CREATE PROCEDURE mysp INSERT INTO t VALUES(1);
· CALL mysp;
이 예문에서 보면, CREATE PROCEDURE 및 CALL 명령문은 바이너리 로그에서 나타나지만, INSERT 명령문은 나타나지 않는다. 이것은 MySQL 5.0.6 이전 버전에서 발생했던 INSERT만 로그되는 문제를 해결해 준다.
CALL 명령문 로깅은 리플리케이션에 대한 보안 문제를 갖게 되는데, 두 가지 요소로 인해 이런 문제가 생긴다:
프로시저가 마스터와 슬레이브 서버상에 있는 서로 다른 실행 경로를 따라갈 수 있게 한다.
슬레이브에서 실행되는 명령문은 전체 권한을 갖고 있는 슬레이브 SQL 쓰레드(Thread)에 의해 실행된다.
비 록 사용자가 루틴을 생성하기 위해서는 반드시 CREATE ROUTINE권한을 가져야 함을 의미 하지만, 전체 권한을 갖는 SQL 쓰레드가 실행하는 명령문이 있는 슬레이브 위에서만 실행될 위험한 명령문을 작성할 수 있다. 예를 들면, 마스터 와 슬레이브 서버가 서버 ID 1과 2를 갖고 있다면, 마스터 서버의 사용자는 아래와 같이 불안정한 프로시저 unsafe_sp() 를 생성해서 호출할 수 있다:
mysql> delimiter //
mysql> CREATE PROCEDURE unsafe_sp ()
-> BEGIN
-> IF @@server_id=2 THEN DROP DATABASE accounting; END IF;
-> END;
-> //
mysql> delimiter ;
mysql> CALL unsafe_sp();
CREATE PROCEDURE 와 CALL 명령문은 바이너리 로그를 작성할 수 있고, 따라서 슬레이브는 이것을 실행할 수 있다. 슬레이브 SQL 쓰레드는 전체 권한이 있기 때문에, accounting 데이터 베이스를 끝내는(drop) DROP DATABASE 명령문을 실행한다. 따라서, CALL 명령문은 마스터와 슬레이브에서 서로 다른 영향을 받게 되고, 이것은 리플리케이션이 안전하게 이루어 지지 않게 된다.
앞선 예문은 스토어드 프로시저를 사용하고 있으나, 바이너리 로그를 작성하는 명령문 내에서 호출되는 스토어드 함수에 대해서도 비슷한 문제가 발생한다: 함수 호출은 마스터와 슬레이브에 서로 다른 효과를 나타낸다.
바 이너리 로깅을 갖는 서버에 대해 이러한 위험을 피하도록 하기 위해, MySQL 5.0.6은 스토어드 프로시저와 함수는 반드시 일반적인 CREATE ROUTINE 권한을 요구하는 것과 아울러 SUPER권한을 갖도록 한다. 비슷하게, ALTER PROCEDURE 또는 ALTER FUNCTION을 사용하기 위해서는, ALTER ROUTINE
1.2.2 MASTER 계정생성 ¶
master mysql > GRANT REPLICATION SLAVE ON *.* -> TO 'user_name'@'user_host' IDENTIFIED BY 'user_password';
master mysql > GRANT FILE ON *.* -> TO 'user_name'@'user_host' IDENTIFIED BY 'user_password';
1.2.3 MASTER 데이터 SLAVE 에 복사 ¶
master mysql > FLUSH TABLES WITH READ LOCK; master shell > tar -cvf /tmp/mysql-snapshot.tar . slave shell > tar -xvf /tmp/mysql-snapshot.tar master mysql > UNLOCK TABLES;
master Shell > mysqldump -u root -p ‘password’ -B db_name > dump_file.sql
1.2.4 MASTER 환경설정 ¶
master shell> vi /etc/my.cnf
[mysqld]
log-bin
server-id = 1
1.2.5 SLAVE 환경설정 ¶
slave shell> vi /etc/my.cnf
[mysqld] server-id = 2 master-host = xxx.xxx.xxx.xxx(user_host) master-port = 3306 master-user = user_name master-password = user_password
1.2.7 SLAVE 덤프파일 LOAD ¶
slave shell > mysql -u root -p < dump_file.sql
1.2.8 MASTER 계정 설정 ¶
slave mysql > CHANGE MASTER TO -> MASTER_HOST='master_host_name', -> MASTER_USER='replication_user_name', -> MASTER_PASSWORD='replication_password', -> MASTER_LOG_FILE='recorded_log_file_name', -> MASTER_LOG_POS=recorded_log_position;
MASTER_HOST 60 MASTER_USER 16 MASTER_PASSWORD 32 MASTER_LOG_FILE 255
1.2.10 SUCCESS CERTIFICATION ¶
Slave I/O thread: connected to master 'user_name@user_host:3306', replication started in log 'FIRST' at position 4
1.3 How to Set Up Dual-Master Replication ¶
1.3.1 SLAVE STOP ¶
mysql2 shell > /etc/init.d/mysqld stop
1.3.4 GRANT REPLICATION SLAVE ¶
mysql2 mysql > GRANT REPLICATION SLAVE ON *.* -> TO 'users_name'@'users_host' IDENTIFIED BY 'users_password';
1.3.5 MASTER SETUP ¶
mysql1 shell > /etc/init.d/mysqld stop
1.3.6 MASTER CONFIGURATION ¶
[mysqld] server-id = 1 <= 그대로 두고, 아래 내용을 추가한다. master-host = users_host master-port = 3306 master-user = users_name master-password = users_password
1.3.8 SUCCESS CERTIFICATION ¶
Slave I/O thread: connected to master 'ccotti@222.112.137.172:3306', replication started in log 'FIRST' at position 4
1.4 장애복구 ¶
mysql1 shell > /etc/init.d/mysqld start
mysql2 mysql > slave stop; mysql2 mysql > slave reset; mysql2 mysql > slave start;
1.5 참고 ¶
Windows에서 MySQL 설치하기
|
Windows에서는 MSI(Microsoft Windows Installer)를 사용한다. Windows 2000 / XP / 2003 Server에서 사용할 수 있으며, http://dev.mysql.com/downloads/mysql/5.0.html에서 다운로드받을 수 있다("Windows Downloads"로 검색하라). 필수 설치 파일을 받았다면 더블클릭하여 실행한다.
다음 설명은 Windows용 MySQL 5.0.22 기준이다. 설치 과정은 Windows 환경에는 독립적이다.
[노트]
MSI 형식 이외의 설치 방법도 제공한다. "Complete Package" 방식과 "Noinstall Archive" 방식이 그것이다. "Essentials Package" 이외의 방법을 사용한다면 MySQL 매뉴얼을 반드시 읽어보아야 한다. 매뉴얼은 http://dev.mysql.com/doc/refman/5.0/en/windows-choosing-package.html에서 구할 수 있다.
본격적으로 설치를 시작해보자(MySQL AB 웹 사이트에서 MSI 파일을 다운로드했다고 가정한다).
1. MSI 파일을 더블클릭한다. [그림 2-4]와 같은 화면이 나오면 [Next] 버튼을 누른다.
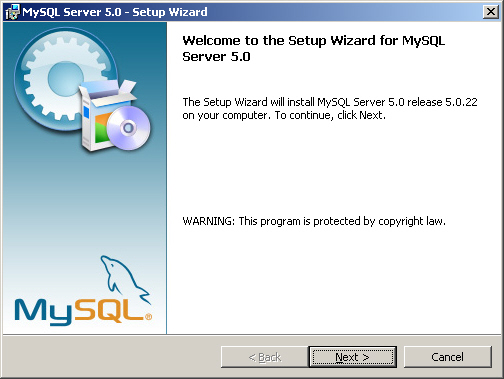
[그림 2-4] Windows용 설치 마법사 시작 화면
2. "Typical", "Complete" 또는 "Custom" 중에 하나를 선택한다([그림 2-5] 참조). "Custom"은 MySQL의 구성 요소들을 선택적으로 설치할 수 있다. "Complete"는 MySQL의 모든 요소를 설치한다. 즉, 문서에서 벤치마킹까지 MySQL 전체를 설치한다. "Typical"은 클라이언트와 서버 그리고 일반적으로 필요한 도구들을 설치해준다. 대부분의 사용자들에게는 "Typical"이 적당하므로 "Typical"을 선택하고 [Next] 버튼을 클릭한다.
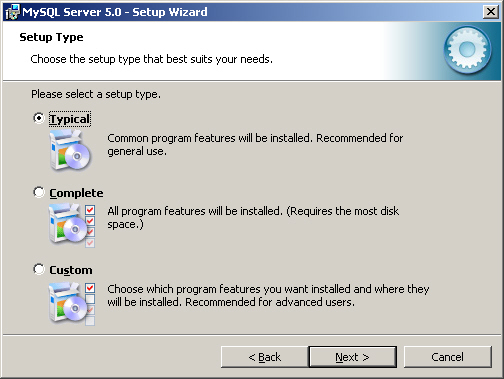
[그림 2-5] 설치 유형을 선택한다.
3. 앞서 선택했던 것을 다시 확인하고 [Install] 버튼을 클릭하면 설치가 시작된다.
[노트]
설치를 하다보면 MySQL.com 계정이 필요할 것이다. 이 계정은 여러분이 설치하고 있는 데이터베이스와는 전혀 관련이 없다. 단지 MySQL.com 웹 사이트의 계정일 뿐이다. 계정을 가지고 있지 않다면 계정을 생성해야 한다. 참고로 이런 등록 절차는 생략할 수 있다.
4. 설치가 완료되면 "MySQL Configuration Wizard"를 설치할 것인지 묻는다. 이 마법사는 반드시 설치해야 한다. 왜냐하면, 여러분의 필요에 맞게 my.ini 파일을 생성해주기 때문이다. "MySQL Configuration Wizard"를 설치하기 위해서 "Configure the MySQL Server Now" 체크 상자를 선택하자([그림 2-6] 참조).
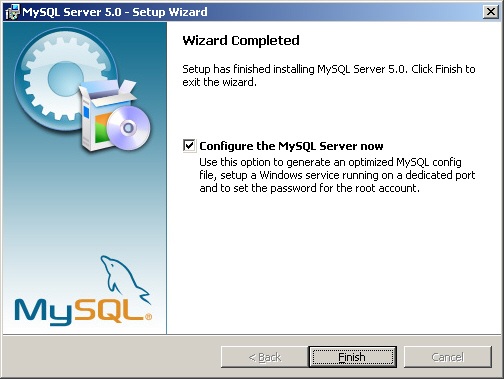
[그림 2-6] MySQL 설치 후 Configuration Wizard를 설치하는 것이 좋다.
5. "MySQL Configuration Wizard"가 실행되면 간단한 환영 메시지가 나온다. [Next] 버튼을 클릭하면 "Detailed"와 "Standard" 설치 방법 중에 하나를 선택할 수 있다. 우리는 가능한 옵션을 모두 확인하기 위해서 "Detail" 방식을 선택할 것이다. "Standard" 방식을 선택할 경우, 설정 변경을 하려면 직접 my.ini 파일을 수정해야 한다. "Detailed" 라디오 버튼을 선택하고 [Next] 버튼을 클릭한다.
6. 다음 단계는 서버 머신 타입을 결정한다. [그림 2-7]과 같이 "Developer Machine", "Server Machine", "Dedicated MySQL Server Machine"을 선택할 수 있다. 서버 머신 타입에 따라서 메모리, 디스크, 프로세서의 할당이 달라진다. 개인 컴퓨터에서 테스트 목적으로 MySQL을 설치한다면 "Developer Machine"을 선택해야 한다. 서버용 머신에서 다른 서버와 함께 MySQL을 설치하려면 "Server Machine"을 선택해야 한다. MySQL을 위한 전용 서버 머신이 준비된 경우라면 "Dedicated MySQL Server Machine"을 선택하는 것이 좋다. 이 경우 대부분의 시스템 자원을 MySQL에 할당해준다.
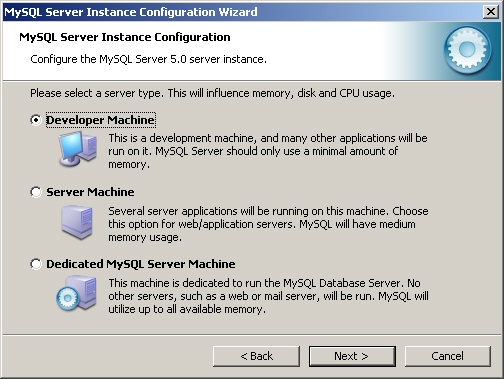
[그림 2-7] 서버 머신 타입의 설정
7. 다음 설정은 데이터베이스 사용에 대한 것이다. "Multifunctional Database"는 InnoDB와 MyISAM 엔진에 균등하게 자원을 배분한다. "Transaction Database"는 InnoDB와 MyISAM 엔진을 모두 사용할 수 있지만, InnoDB에 대부분의 자원을 할당한다. "Non-Transactional Database"는 MyISAM 엔진에 모든 자원을 할당한다. 즉, InnoDB는 사용할 수 없다. 여러분의 사용 패턴을 확신할 수 없다면 "Multifunctional Database"를 선택하는 것이 좋다.
8. InnoDB 저장 엔진이 활성화되었다면 [그림 2-8]과 같이 저장 관련 정보를 설정해야 한다. [그림 2-8]은 초기 설정 상태이다. 원한다면 설정을 바꿔도 좋다. [Next] 버튼을 클릭하면 다음 단계로 넘어간다.
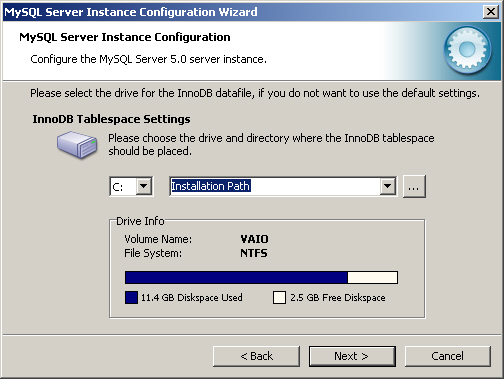
[그림 2-8] InnoDB 저장 엔진을 위한 디스크 튜닝
9. MySQL 서버의 동시 접속수를 지정한다. 동시 접속수는 데이터베이스의 사용 패턴과 트래픽 정도에 따라서 달라져야 한다. "Decision Support (DSS)/OLAP"이 기본 설정이다. 기본 설정은 최대 100개의 동시 접속을 허용하며, 평균적으로 20개의 동시 접속이 있다고 가정한다. "Online Transaction Processing(OLTP)"은 최대 500개의 동시 접속을 허용한다. "Manual Setting"은 여러분이 직접 동시 접속수를 지정할 수 있도록 해준다. 동시 접속에 대한 결정을 했다면 [Next] 버튼을 클릭한다.
10. 다음은 네트워크 옵션 설정이다. TCP/IP 사용여부와 포트를 지정할 수 있다. 기본 포트는 3306이지만, 다른 포트(사용중이지 않은 포트)로 변경할 수 있다. TCP/IP 이외에 "Enable Strict Mode" 사용여부도 지정할 수 있다. "Strict Mode"가 무엇인지 잘 모르겠다면 "Enable Strict Mode"를 선택된 상태로 두는 것이 좋다. 좀 더 자세한 정보가 필요하다면http://dev.mysql.com/doc/refman/5.0/en/server-sql-mode.html을 방문해보자. 모든 선택이 끝났다면 [Next] 버튼을 클릭한다.
[노트]
TCP/IP 설정에서 지정한 포트를 위해 방화벽 수정이 필요하다. 즉, 3306포트(직접 포트를 지정했다면 다를 수 있다)를 위한 방화벽 흐름제어가 필요하다.
11. 다음은 문자세트을 지정한다. 기본 옵션은 "Standard Character Set"으로 "Latin1"을 사용한다. "Best Support for Mulilingualism"은 UTF8을 사용한다. UTF8은 하나의 문자세트로 다국어를 표현할 수 있다. "Manual Selected Default Character Set"은 직접 문자세트를 선택할 수 있게 해준다. 이 항목을 선택하면 적당한 문자 세트를 선택할 수 있도록 드롭다운 리스트가 나온다. 설정을 마쳤으면 [Next] 버튼을 클릭한다.
12. MySQL은 서비스 형태로 설치하는 것이 좋다. [그림 2-9]는 이와 관련된 설정 화면이다. "Install As Windows Service" 체크 상자를 체크하고 서비스 이름을 선택한다. 원한다면 "Launch the MySQL Server Automatically"를 체크해도 좋다. 참고로, MySQL의 bin 폴더를 Windows PATH 환경변수에 추가하면 cmd 창에서 MySQL를 쉽게 접근할 수 있다. 설정을 마쳤으면 다음으로 넘어간다.
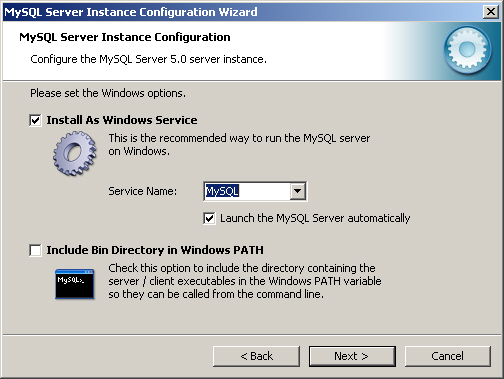
[그림 2-9] MySQL 서버 인스턴스 설정
13. 다음은 보안 옵션에 대한 설정으로 가장 중요하다. [그림 2-10]과 같이 root 암호를 지정한다. 암호를 두 번 입력하여 오타 여부를 다시 확인한다. "Enable Root Access"는 의미를 잘 알고 있는 경우에만 선택하는 것이 좋다. 일반적으로 root 접근은 로컬로 제한하는 것이 보통이다. 익명 접근을 허용할 수도 있지만 추천하지는 않는다. 보안에 좋지 않기 때문이다. 설정을 마쳤으면 [Next] 버튼을 클릭한다.
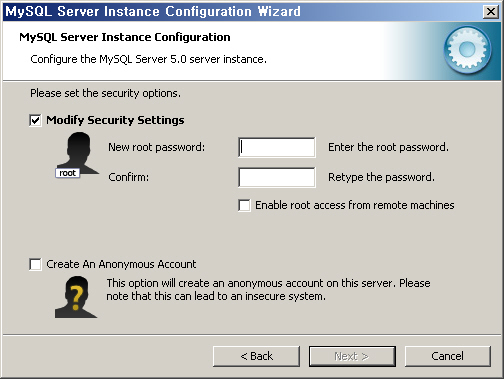
[그림 2-10] root 암호를 지정한다.
14. 이제 마지막 단계이다. [Execute] 버튼을 클릭하면 화면에 나열된 순서대로 처리를 시작한다. 모든 처리가 끝나면 [그림 2-11]과 같은 화면을 볼 수 있다.
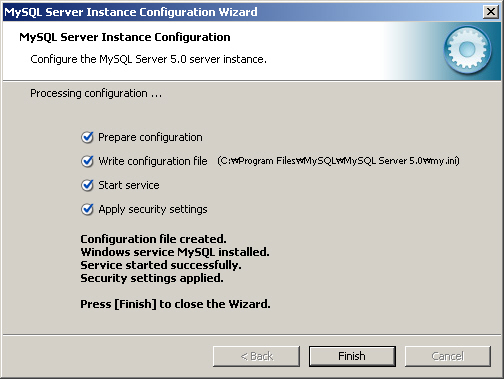
[그림 2-11] MySQL Configuration Wizard의 성공적인 종료
"MySQL Configuration Wizard"는 my.ini 설정 파일을 "C:\Program Files\MySQL\MySQL Server 5.0\"에 만들고 MySQL 서비스를 시작시켜 주는 것으로 인스톨 및 설정 과정을 마무리한다.
[팁]
my.ini 파일을 직접 수정하는 것도 가능하다. 수정 후에는 반드시 MySQL 서버를 다시 시작해야 한다.
 Prev
Prev
